
- Saltar a la navegación principal
- Saltar al contenido principal
- Saltar a la barra lateral principal
- Saltar al pie de página
Bluetab
an IBM Company
Basic AWS Glue concepts

Álvaro Santos
Senior Cloud Solution Architect

At Cloud Practice we aim to encourage adoption of the cloud as a way of working in the IT world. To help with this task, we are going to publish numerous good practice articles and use cases and others will talk about those key services within the cloud.
We present the basic concepts AWS Glue below.
What is AWS Glue?
AWS Glue is one of those AWS services that are relatively new but have enormous potential. In particular, this service could be very useful to all those companies that work with data and do not yet have powerful Big Data infrastructure.
Basically, Glue is a fully AWS-managed pay-as-you-go ETL service without the need for provisioning instances. To achieve this, it combines the speed and power of Apache Spark with the data organisation offered by Hive Metastore.
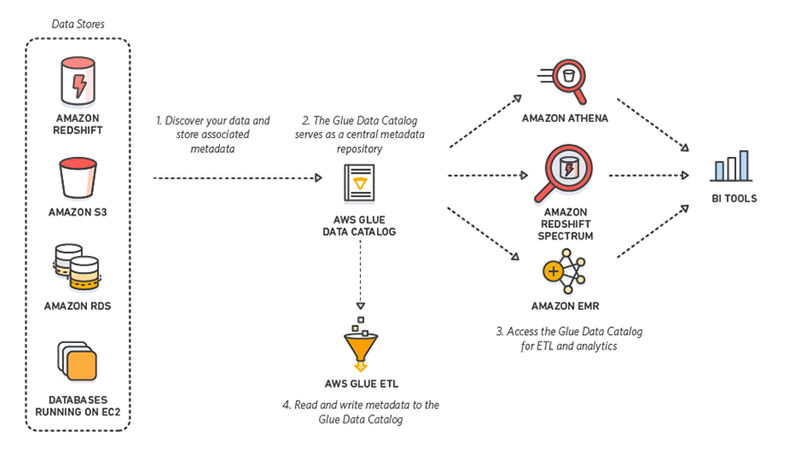
AWS Glue Data Catalogue
The Glue Data Catalogue is where all the data sources and destinations for Glue jobs are stored.
- Table is the definition of a metadata table on the data sources and not the data itself. AWS Glue tables can refer to data based on files stored in S3 (such as Parquet, CSV, etc.), RDBMS tables…
- Database refers to a grouping of data sources to which the tables belong.
- Connection is a link configured between AWS Glue and an RDS, Redshift or other JDBC-compliant database cluster. These allow Glue to access their data.
- Crawler is the service that connects to a data store, it progresses through a prioritised list of classifiers to determine the schema for the data and to generate the metadata tables. They support determining the schema of complex unstructured or semi-structured data. This is especially important when working with Parquet, AVRO, etc. data sources.
ETL
An ETL in AWS Glue consists primarily of scripts and other tools that use the data configured in the Data Catalogue to extract, transform and load the data into a defined site.
- Job is the main ETL engine. A job consists of a script that loads data from the sources defined in the catalogue and performs transformations on them. Glue can generate a script automatically or you can create a customised one using the Apache Spark API in Python (PySpark) or Scala. It also allows the use of external libraries which will be linked to the job by means of a zip file in S3.
- Triggers are responsible for running the Jobs. They can be run according to a timetable, a CloudWatch event or even a cron command.
- Workflows is a set of triggers, crawlers and jobs related to each other in AWS Glue. You can use them to create a workflow to perform a complex multi-step ETL, but that AWS Glue can run as a single entity.
- ML Transforms are specific jobs that use Machine Learning models to create custom transforms for data cleaning, such as identifying duplicate data, for example.
- Finally, you can also use Dev Endpoints and Notebooks, which make it faster and easier to develop and test scripts.
Examples
Sample ETL script in Python:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
## Read Data from a RDS DB using JDBC driver
connection_option = {
"url": "jdbc:mysql://mysql–instance1.123456789012.us-east-1.rds.amazonaws.com:3306/database",
"user": "test",
"password": "password",
"dbtable": "test_table",
"hashexpression": "column_name",
"hashpartitions": "10"
}
source_df = glueContext.create_dynamic_frame.from_options('mysql', connection_options = connection_option, transformation_ctx = "source_df")
job.init(args['JOB_NAME'], args)
## Convert DataFrames to *AWS Glue* 's DynamicFrames Object
dynamic_df = DynamicFrame.fromDF(source_df, glueContext, "dynamic_df")
## Write Dynamic Frame to S3 in CSV format
datasink = glueContext.write_dynamic_frame.from_options(frame = dynamic_df, connection_type = "s3", connection_options = {
"path": "s3://glueuserdata"
}, format = "csv", transformation_ctx = "datasink")
job.commit() Creating a Job using a command line:
aws glue create-job --name python-job-cli --role Glue_DefaultRole \
--command '{"Name" : "my_python_etl", "ScriptLocation" : "s3://SOME_BUCKET/etl/my_python_etl.py"}' Running a Job using a command line:
aws glue start-job-run --job-name my_python_etl AWS has also published a repository with numerous example ETLs for AWS Glue.
Security
Like all AWS services, it is designed and implemented to provide the greatest possible security. Here are some of the security features that AWS GLUE offers:
- Encryption at Rest: this service supports data encryption (SSE-S3 or SSE-KMS) at rest for all objects it works with (metadata catalogue, connection password, writing or reading of ETL data, etc.).
- Encryption in Transit: AWS offers Secure Sockets Layer (SSL) encryption for all data in motion, AWS Glue API calls and all AWS services, such as S3, RDS…
- Logging and monitoring: is tightly integrated with AWS CloudTrail and AWS CloudWatch.
- Network security: is capable of enabling connections within a private VPC and working with Security Groups.
Price
AWS bills for the execution time of the ETL crawlers / jobs and for the use of the Data Catalogue.
- Crawlers: only crawler run time is billed. The price is $0.44 (eu-west-1) per hour of DPU (4 vCPUs and 16 GB RAM), billed in hourly increments.
- Data Catalogue: you can store up to one million objects at no cost and at $1.00 (eu-west-1) per 100,000 objects thereafter. In addition, $1 (eu-west-1) is billed for every 1,000,000 requests to the Data Catalogue, of which first million is free.
- ETL Jobs: billed only for the time the ETL job takes to run. The price is $0.44 (eu-west-1) per hour of DPU (4 vCPUs and 16 GB RAM), billed by the second.
Benefits
Although it is a young service, it is quite mature and is being used a lot by clients all over the AWS world. The most important features it offers us are:
- It automatically manages resource escalation, task retries and error handling.
- It is a Serverless service, AWS manages the provisioning and scaling of resources to execute the commands or queries in the Apache Spark environment.
- The crawlers are able to track your data, suggest schemas and store them in a centralised catalogue. They also detect changes in them.
- The Glue ETL engine automatically generates Python / Scala code and has a programmer including dependencies. This facilitates development of the ETLs.
- You can directly query the S3 data using Athena and Redshift Spectrum using the Glue catalogue.
Conclusions
Like any database, tool, or service offered, AWS Glue has certain limitations that would need to be considered to adopt it as an ETL service. You therefore need to bear in mind that:
- It is highly focused on working with data sources in S3 (CSV, Parquet, etc.) and JDBC (MySQL, Oracle, etc.).
- The learning curve is steep. If your team comes from the traditional ETL world, you will need to wait for them to pick up understanding of Apache Spark.
- Unlike other ETL tools, it lacks default compatibility with many third-party services.
- It is not a 100% ETL tool in use and, as it uses Spark, code optimisations need to be performed manually.
- Until recently (April 2020), AWS Glue did not support streaming data. It is too early to use AWS Glue as an ETL tool for real-time data.
Do you want to know more about what we offer and to see other success stories?
Álvaro Santos
Senior Cloud Solution Architect
My name is Álvaro Santos and I have been working as Solution Architect for over 5 years. I am certified in AWS, GCP, Apache Spark and a few others. I joined Bluetab in October 2018, and since then I have been involved in cloud Banking and Energy projects and I am also involved as a Cloud Master Partitioner. I am passionate about new distributed patterns, Big Data, open-source software and anything else cool in the IT world.
SOLUTIONS, WE ARE EXPERTS
You may be interested in





Conceptos básicos de AWS Glue
Álvaro Santos
Senior Cloud Solution Architect
Desde la Práctica Cloud queremos impulsar la adopción de la nube como forma de trabajo en el mundo de IT. Para ayudar en esta tarea, vamos a publicar multitud de artículos de buenas prácticas y casos de uso, otros hablarán aquellos servicios clave dentro de la nube.
A continuación os vamos a presentar los conceptos básicos de AWS Glue.
¿Qué es AWS Glue?
AWS Glue es uno de esos servicios de AWS que son relativamente nuevos pero que tienen un enorme potencial. En especial este servicio puede ser muy beneficioso para todas aquellas empresas que trabajan con datos y que aún no posean una infraestructura de Big Data potente.
Básicamente, Glue es un servicio de ETLs totalmente administrado por AWS y de pago por uso sin necesidad de aprovisionar instancias. Para conseguirlo, combina la velocidad y potencia de Apache Spark con la organización de datos que ofrece Hive Metastore.
AWS Glue Data Catalog
El Catálogo de datos de Glue es donde se almacenan todos los orígenes y destinos de datos para los trabajos de Glue.
- Table es la definición de una tabla de metadatos sobre las fuentes de datos y no los datos en sí. Las tablas de AWS Glue pueden referirse datos basados en archivos almacenados en S3 (como Parquet, CSV…), tablas de RDBMS…
- Database se refiere a una agrupación de fuentes de datos a las que pertenecen las tablas.
- Connection es un enlace configurado entre AWS Glue y un cluster de RDS, Redshift u otra BBDD compatible con JDBC. Estas permiten que Glue acceda a sus datos.
- Crawler es el servicio encargado de conectarse a un almacén de datos, avanza a través de una lista priorizada de clasificadores para determinar el esquema de los datos y de generar las tablas de metadatos. Son compatibles de determinar el esquema de datos complejos no estructurados o semi-estructurados. Ésto es especialmente importante cuando se trabajan con fuentes de datos de tipo Parquet, AVRO, …
ETL
Una ETL en AWS Glue está compuesta principalmente de los scripts y otras herramientas que utilizan los datos configurados en Data Catalog para extraer, transformar y cargar los datos en un sito definido.
- Job es el motor principal de la ETL. Un trabajo consiste en un script que carga datos de las fuentes definidas en el catálogo y realiza transformaciones sobre ellos. Glue puede generar automáticamente un script, o se puede crear uno personalizado usando la API de Apache Spark en Python (PySpark) o Scala. Además, se permite el uso de bibliotecas externas que vinculara al trabajo mediante un archivo zip en S3.
- Triggers se encargan de ejecutar los Jobs. Pueden ejecutarse según un cronograma, un evento de CloudWatch o incluso un comandos cron.
- Workflows es un conjunto triggers, crawlers y jobs relacionados entre sí en AWS Glue. Con ellos se puede crear un flujo de trabajo para realizar una ETL compleja de varios pasos pero que AWS Glue puede ejecutar como entidad única.
- ML Transforms son unos trabajos específicos que mediante modelos de Machine Learning crean transformaciones personalizadas para la limpieza de los datos como por ejemplo identificación de datos duplicados.
- Finalmente, también es posible usar Dev Endpoints y Notebooks, que facilitan el desarrollo y probar los scripts de manera más rápida y sencilla.
Ejemplos
Script de ejemplo de ETL en Python:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
## Read Data from a RDS DB using JDBC driver
connection_option = {
"url": "jdbc:mysql://mysql–instance1.123456789012.us-east-1.rds.amazonaws.com:3306/database",
"user": "test",
"password": "password",
"dbtable": "test_table",
"hashexpression": "column_name",
"hashpartitions": "10"
}
source_df = glueContext.create_dynamic_frame.from_options('mysql', connection_options = connection_option, transformation_ctx = "source_df")
job.init(args['JOB_NAME'], args)
## Convert DataFrames to *AWS Glue* 's DynamicFrames Object
dynamic_df = DynamicFrame.fromDF(source_df, glueContext, "dynamic_df")
## Write Dynamic Frame to S3 in CSV format
datasink = glueContext.write_dynamic_frame.from_options(frame = dynamic_df, connection_type = "s3", connection_options = {
"path": "s3://glueuserdata"
}, format = "csv", transformation_ctx = "datasink")
job.commit() Creación de un Job mediante línea de comandos:
aws glue create-job --name python-job-cli --role Glue_DefaultRole \
--command '{"Name" : "my_python_etl", "ScriptLocation" : "s3://SOME_BUCKET/etl/my_python_etl.py"}' Ejecución de un Job mediante línea de comandos:
aws glue start-job-run --job-name my_python_etl Además, AWS tiene publicado un repositorio con multitud de ejemplos de ETLs para AWS Glue.
Seguridad
Como todo servicio de AWS, está diseñado e implementado para ofrecer la mayor seguridad posible. Estas son algunas de las funcionalidades de seguridad que ofrece AWS GLUE:
- Cifrado en Reposo: este servicio admite el cifrado de datos (SSE-S3 o SSE-KMS) en reposo para todos los objetos que trabaja (catálogo de metadatos, contraseña de conexiones, escritura o lectura de los datos de la ETL, …).
- Cifrado en Tránsito: AWS ofrece cifrado de conexión segura (SSL) para todos los datos en movimiento, las llamadas a la API de AWS Glue y a todos los servicios de AWS como S3, RDS…
- Registro y monitorización: está fuertemente integrado con AWS CloudTrail y AWS CloudWatch.
- Seguridad de red: es capaz de habilitar conexiones dentro de una VPC privada y trabajar con Security Groups.
Precio
AWS factura por el tiempo de ejecución de los crawlers / jobs de ETLs y por el uso de Data Catalog.
- Crawlers: se factura sólo por el tiempo de ejecución del crawler. El precio es de $0.44 (eu-west-1) por cada hora de DPU (4 vCPUs y 16 GB RAM) facturados en tramos de hora.
- Data Catalog: se puede almacenar hasta un millón de objetos de manera gratuita y a partir de ahí $1.00 (eu-west-1) cada 100.000 objetos. Además, se factura $1 (eu-west-1) por cada 1.000.000 de peticiones al Data Catalog de las cuales el 1er millón es gratuito.
- ETL Jobs: se factura sólo por el tiempo que el trabajo de ETL demore en ejecutarse. El precio es de $0.44 (eu-west-1) por cada hora de DPU (4 vCPUs y 16 GB RAM) facturados por segundo.
Beneficios
Pese a ser un servicio joven es bastante maduro y se está usando mucho por clientes del todo el mundo de AWS. Las características más importantes que nos aporta son:
- Gestiona automáticamente el escalado de recursos, reintentos de tareas y gestión de errores automáticamente.
- Es un servicio Serverless, AWS maneja el aprovisionamiento y escalado de los recursos para ejecutar los comandos o consultas en el entorno Apache Spark.
- Los crawlers son capaces de rastrear tus datos, sugerir esquemas y almacenarlos en un catálogo centralizado. Además, son detectan cambios en los mismos.
- El motor ETL de Glue genera automáticamente código Python / Scala y tiene un programador incluyendo dependencias. De este modo, facilita el desarrollo de las ETLs.
- Usando el catálogo Glue, podemos consultar directamente los datos S3 usando Athena y Redshift Spectrum.
Conclusiones
Como toda Base de Datos, herramienta o servicio ofrecido, AWS Glue tiene ciertas limitaciones que habría que tener en cuenta para adoptarlo como servicio de ETLs. Por ello deberías tener presente que:
- Está muy enfocado a trabajar con fuentes de datos en S3 (CSV, Parquet…) y JDBC (MySQL, Oracle…).
- La curva de aprendizaje es alta. Si tu equipo viene del mundo de ETL tradicional, tendrás que esperar a que gane conocimientos de Apache Spark.
- Al contrario que otras herramientas de ETLS, carece por defecto de compatibilidad con muchos servicios de terceros.
- No es una herramienta de ETLs 100% al uso y, puesto que usa Spark, es necesario realizar optimizaciones en el código manualmente.
- Hasta hace poco (abril 2020), AWS Glue no soportaba fuente de datos en streaming. Es demasiado prematuro usar AWS Glue como herramienta de ETLS para datos en tiempo real.
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
Álvaro Santos
Senior Cloud Solution Architect
Mi nombre es Álvaro Santos y ejerzo como Solution Architect desde hace más de 5 años. Estoy certificado en AWS, GCP, Apache Spark y alguna que otras más. Entré a formar parte en Bluetab en octubre de 2018 y desde entonces estoy involucrado en proyectos cloud de Banca y Energía y además participo como Cloud Master Partitioner. Soy un apasionado de las nuevas patrones distribuidos, Big Data, Open-source software y cualquier otra cosa de mundo IT que mole.
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar




Footer



© 2025 Bluetab Solutions Group, SL. All rights reserved.