
- Saltar a la navegación principal
- Saltar al contenido principal
- Saltar a la barra lateral principal
- Saltar al pie de página
Bluetab
an IBM Company

Alvaro Santos
Senior Cloud Solution Architect


Aunque es cierto que Redshift se basó en una versión antigua de PostgreSQL 8.0.2, su arquitectura ha cambiado radicalmente y ha sido optimizada durante años para mejorar el redimiendo para su estrictamente analítico. Por ellos es necesario:
- Diseñar las tablas de manera adecuada.
- Lanzar consultas optimizadas para entornos MPP.
Diseñar las tablas de manera adecuada
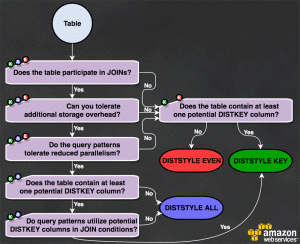
Cuando se diseña la base de datos ten en cuenta que algunas decisiones clave sobre el diseño de las tablas influyen considerablemente en el rendimiento general de la consulta. Unas buenas practicas son:- Seleccionar el tipo de distribución de datos óptima:

- Para las tablas de hechos (facts) elige el tipo
DISTKEY. De esta manera los datos se distribuirán en los diferentes nodos agrupados por los valores de la clave elegida. Esto te permitirá realizar consultas de tipoJOINsobre esa columna de manera muy eficiente. - Para las tablas de dimensiones (dimensions) con un pocos de millones de entradas elige el tipo
ALL. Aquellas tablas que son comúnmente usadas en joins de tipo diccionario es recomendable que se copien a todos los nodos. De esta manera la sentenciaJOINrealizada con tablas de hechos mucho más grandes se ejecutará mucho más rápido. - Cuando no tengas claro como vas a realizar la consulta sobre una tabla muy grande o simplemente no tenga ninguna relación con el resto, elige el tipo
EVEN. De esta forma los datos se distribuirán de manera aleatoria.
- Para las tablas de hechos (facts) elige el tipo
- Usa la compresión automática permitiendo a Redshift que seleccione el tipo más optimo para cada columna. Esto lo consigue realizando un escaneo sobre un número limitado de elementos.
Usar consultas optimizadas para entornos MPP
Puesto que Redshift es un entorno MPP distribuido, es necesario maximizar el rendimiento de las consultas siguiendo unas recomendaciones básicas. Unas buenas practicas son:- Las tablas tiene que diseñarse pensando en las consultas que se van a realizar. Por lo tanto, si una consulta no encaja es necesario que revises el diseño de las tablas que participan.
- Evite usar
SELECT *.e incluye solo las columnas que necesites. - No uses cross-joins a no ser que sea necesario.
- Siempre que puedas, usa la sentencia
WHEREpara restringir la cantidad de datos a leer. - Use claves de ordenación en las cláusulas
GROUP BYySORT BYpara que el planificador de consultas pueda usar una agregación más eficiente.






Footer
