
Bluetab
an IBM Company
Entrena y Despliega tu Modelo de Machine Learning en 15 Minutos con Databricks

Jhon Rojas
Technical Specialist

Introducción
El mundo del machine learning (ML) está evolucionando rápidamente, y herramientas como Databricks están revolucionando cómo los equipos de datos y científicos de datos entrenan y despliegan modelos de ML de manera eficiente. Con su potente infraestructura y capacidades, Databricks hace que todo el proceso de desarrollo de modelos, desde la preparación de los datos hasta el despliegue para la inferencia en tiempo real, sea rápido y escalable. En este blog, se mostrará cómo entrenar y desplegar un modelo de clasificación en Databricks en tan solo 15 minutos.
Entorno Databricks
Se utilizará el entorno de Azure Databricks para realizar una ejecución práctica en la que se creará y desplegará un modelo de Machine Learning. Se ha creado un Workspace de Databricks en la región Central US, de Pricing Tier Standard, dentro del cual se ha creado un Cluster con Databricks Runtime Version 12.2 LTS ML (includes Apache Spark 3.3.2, Scala 2.12) y con 1 Node de Tipo Standard_D4ds_v5.
Dataset
Se utilizará un dataset que proviene de un análisis químico de vinos cultivados en la misma región de Italia, pero derivados de tres cultivares diferentes. El dataset está disponible públicamente en el repositorio de la UCI Machine Learning Repository (https://archive.ics.uci.edu/dataset/109/wine). El conjunto de datos incluye la cantidad de 13 componentes químicos presentes en cada uno de los tres tipos de vino analizados. Estos datos fueron obtenidos para estudiar la relación entre las características químicas del vino y su calidad. El objetivo será generar un modelo de ML para predecir el color de un vino (puede ser rojo o blanco) a partir de sus características químicas.
Repositorio
Los notebooks del ejercicio práctico y los datos usados se encuentran en el siguiente repositorio: https://github.com/jhonrojasbluetab/databricks_ml
Parte 1: Entrena un Modelo de ML Usando Experiments y AutoML
El proceso de entrenar un modelo de machine learning (ML) puede ser complejo y requiere varias etapas, desde la preparación de los datos hasta la selección y ajuste del modelo. Con Databricks, este proceso se simplifica significativamente mediante el uso de AutoML y el módulo Experiments, lo que permite a los usuarios centrarse en tareas de alto nivel, mientras que la plataforma se encarga de las tareas tediosas y técnicas.
1.1 Preparación del Dataset: El Proceso ETL
Antes de empezar a entrenar un modelo, es necesario asegurarse de que los datos estén bien preparados. Esto implica un proceso de ETL (Extracción, Transformación y Carga). Databricks facilita este proceso mediante su integración con Apache Spark. Spark permite procesar datos de manera distribuida y rápida, lo que es ideal para trabajar con grandes volúmenes de información.
El proceso de ETL comienza con la extracción de los datos desde diferentes fuentes, como bases de datos, archivos CSV, archivos Parquet, o incluso desde la web. Gracias a la integración de Databricks con plataformas en la nube como Azure, AWS o GCP, puedes acceder fácilmente a datos almacenados en Azure Blob Storage, Amazon S3 o Google Cloud Storage, entre otros. Una vez que se tienen los datos, es hora de realizar las transformaciones. Esto incluye limpiar los datos, tratar valores faltantes, crear nuevas características (feature engineering), y asegurar que las características estén en el formato adecuado para el modelo. Finalmente, se cargan los datos transformados en una estructura que el modelo puede usar, como un DataFrame de Spark.
Para este caso de uso, se ejecutó el procesó de ETL (el cual no se detallará en este blog porque no es el enfoque de este blog) y se cargaron los datos dentro del Catalog de Databricks. El dataset a utilizar se llama wine_data_df.
1.2 El Módulo Machine Learning de Databricks
Una vez que los datos están listos, podemos pasar al entrenamiento del modelo. Databricks tiene un potente módulo de Machine Learning que te permite llevar a cabo todo el ciclo de vida de un modelo. Uno de los aspectos más útiles es el uso de MLflow, la plataforma de código abierto para la gestión del ciclo de vida completo de los modelos de machine learning (Databricks, 2025a).
MLflow permite entrenar, registrar, desplegar y gestionar modelos de manera sencilla. Uno de los puntos clave aquí es el uso de Experiments en Databricks. Los Experiments permiten organizar y hacer un seguimiento de diferentes ejecuciones de un modelo, lo que te ayuda a comparar los resultados de varias configuraciones y versiones del modelo .
AutoML es otra característica destacada de Databricks, este módulo automatiza muchas de las decisiones que un científico de datos tomaría durante el proceso de entrenamiento de un modelo, como la selección de algoritmos, la optimización de hiperparámetros, y el preprocesamiento de los datos (Databricks, 2025b). AutoML también ofrece una interfaz sencilla para ejecutar modelos de manera eficiente, sin tener que escribir mucho código.
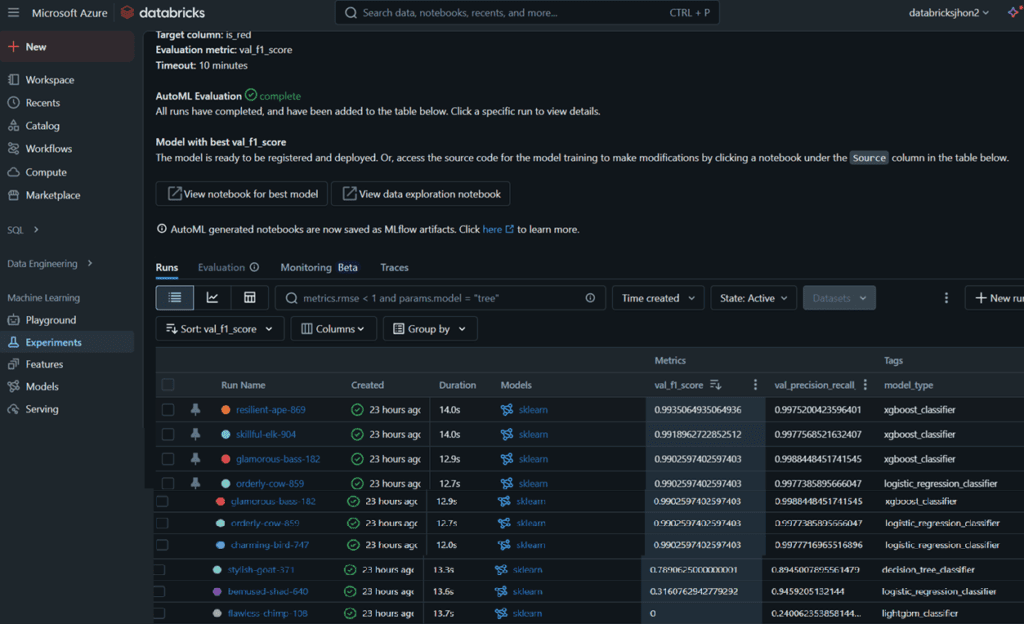
Para este caso de uso, se usó el Módulo de Machine Learning de Databricks para crear un experimento de Clasificación usando el dataset wine_data_df previamente preparado. La variable que se estimará es el color del vino, 1 si es rojo, 0 si es blanco.
Se ha definido que el experimento tiene un tiempo límite de 10 minutos para evaluar diferentes modelos y elegir el mejor con base en la métrica de desempeño F1 (se puede seleccionar la métrica que se desee).
1.3 Exploración Automática de Datos: Estadísticas Descriptivas y Visualización
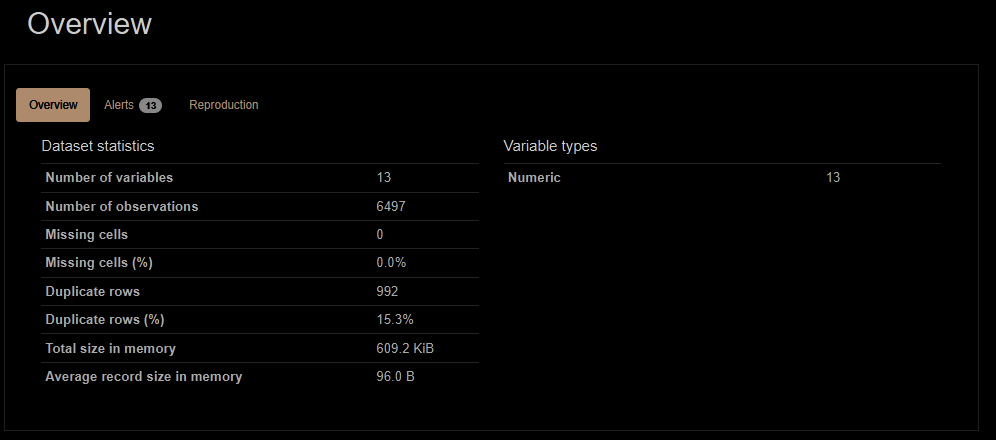
Antes de entrenar el modelo, es esencial realizar un análisis exploratorio de los datos, EDA (Behrens, J. T., 2003), para entender su distribución, detectar posibles outliers (valores atípicos) y descubrir patrones que podrían ser importantes para el modelo. En Databricks, esta exploración se automatiza mediante AutoML, que genera automáticamente estadísticas descriptivas como la media, desviación estándar, mínimos y máximos, valores nulos para cada variable en el conjunto de datos. Además, la plataforma crea visualizaciones interactivas, como histogramas, boxplots y gráficos de dispersión, que permiten detectar de manera visual las distribuciones y las relaciones entre variables. Estas herramientas automáticas de exploración de datos ahorran mucho tiempo y esfuerzo, ya que permiten que los usuarios tengan una visión clara de los datos sin escribir código adicional.
Para este caso de uso, la ejecución del experimento genera inicialmente, y de manera automática, un Notebook con la exploración de datos.
A continuación, se muestran algunos resultados que arroja el notebook, como estadísticas del dataset, detalle exploratorio e histograma de las variables, matriz de correlaciones entre variables.
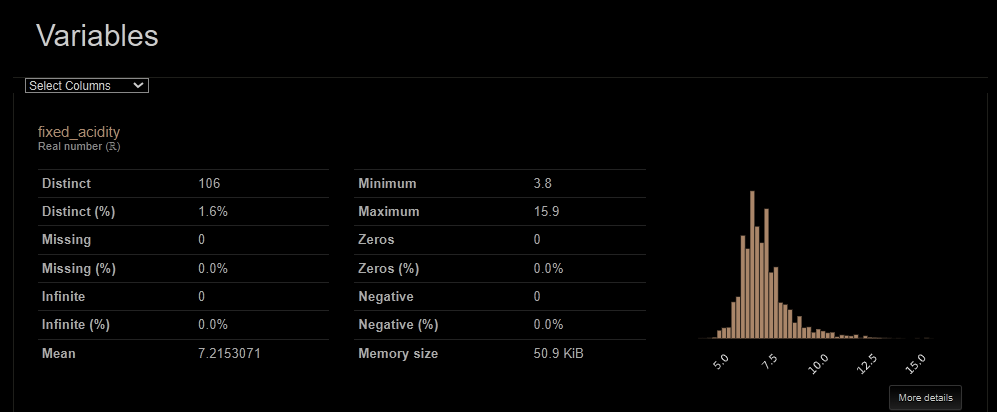
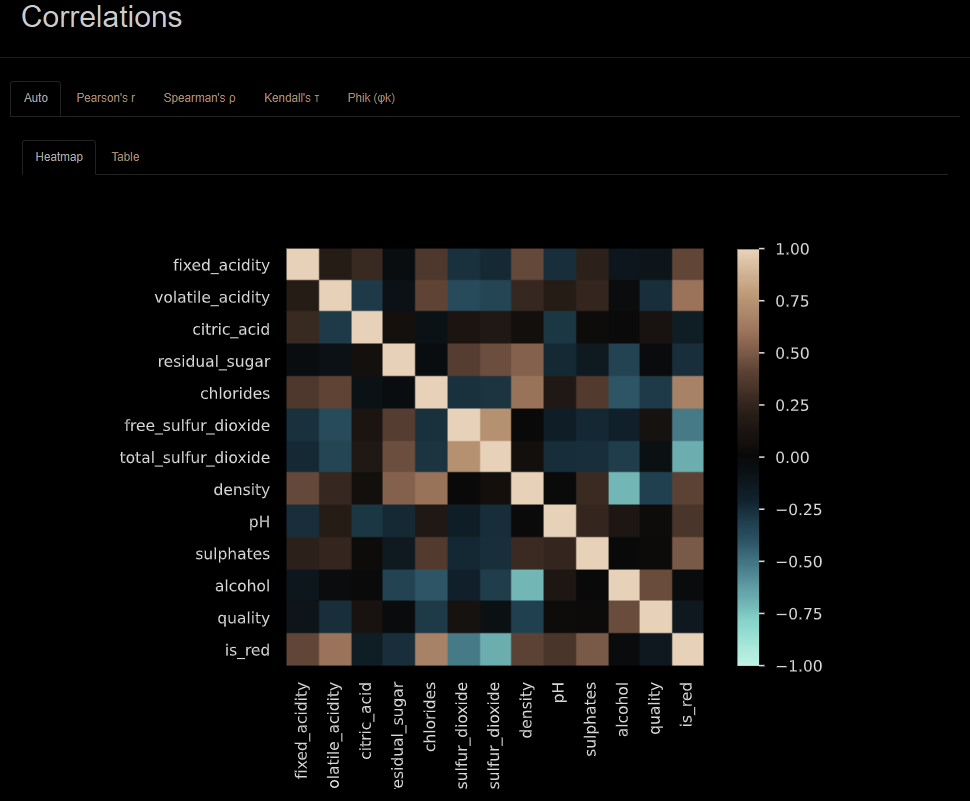
1.4 Modelos Estadísticos y Selección del Mejor Modelo
Una de las grandes ventajas de usar Databricks es su capacidad para probar y evaluar múltiples modelos estadísticos con un mínimo esfuerzo. Cuando entrenas un modelo utilizando AutoML o Experiments, Databricks prueba automáticamente diferentes algoritmos para encontrar el que mejor se adapte a tus datos, para lo cual calcula métricas como precisión, recall, F1-score y AUC-ROC, las cuales sirven para evaluar el desempeño del modelo al medir su capacidad para hacer predicciones correctas y equilibrar entre falsos positivos y falsos negativos (Powers, 2011).
Algunos de los algoritmos más comunes que Databricks puede probar incluyen:
- Regresión logística
- Árboles de decisión
- Máquinas de soporte vectorial (SVM)
- Redes neuronales
- XGBoost
Con el uso de AutoML, Databricks también puede ajustar de forma automática los hiperparámetros de estos modelos, lo que mejora aún más su rendimiento.
Una vez que todos los modelos han sido entrenados, Databricks muestra cuál tiene el mejor rendimiento según las métricas de desempeño, lo que permite seleccionar fácilmente el modelo más adecuado para la tarea. De esta forma, los usuarios no necesitan preocuparse por la implementación de cada modelo, ya que Databricks se encarga de todo el proceso
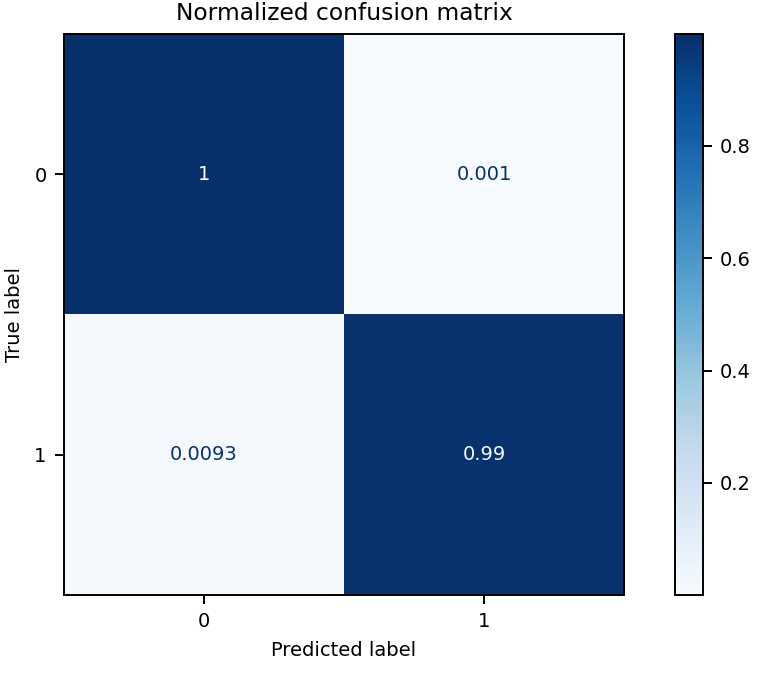
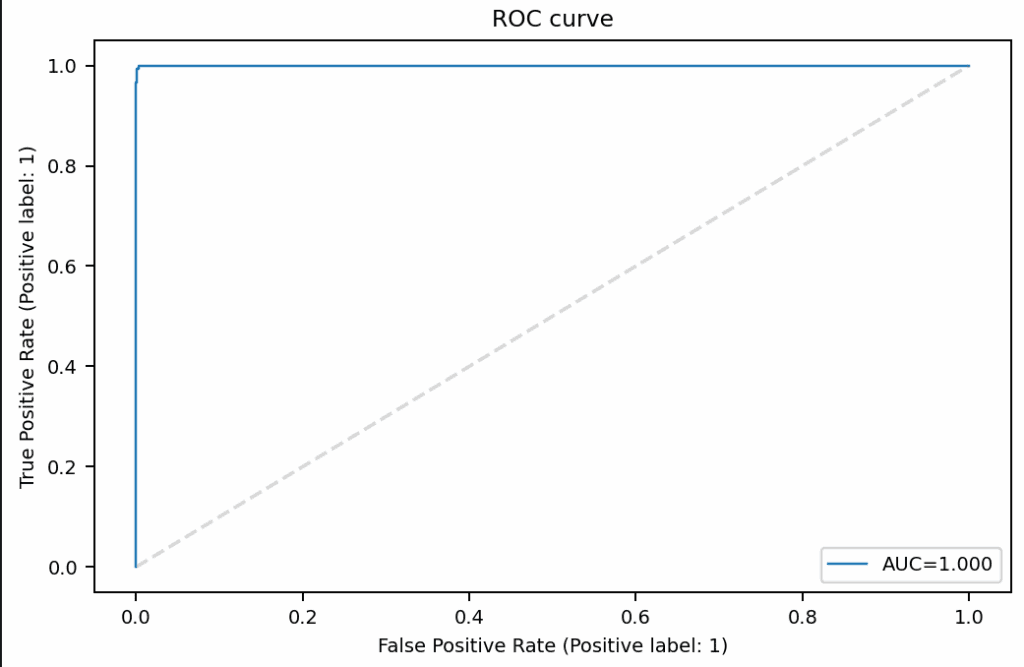
Para este caso de uso, el experimento evaluó 78 modelos, dentro de los cuales hay xgboost, logistic, random forest, classification tree. El mejor modelo fue un xgboost, que obtuvo el valor más alto de F1 (0.993506), este será el modelo elegido porque proporciona la menor cantidad de predicciones incorrectas, tanto en términos de falsos positivos como falsos negativos.
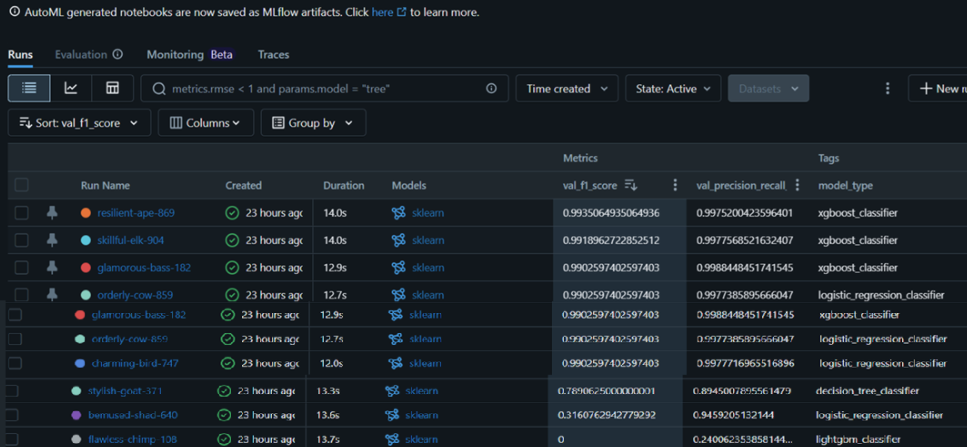
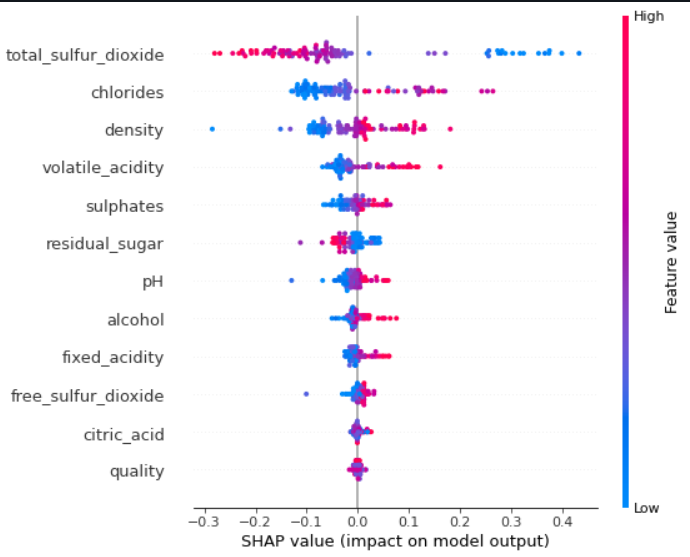
Para el mejor modelo, se genera automáticamente un Notebook que documenta el proceso completo de obtención del modelo, que incluye pasos como la carga de datos, la creación de los conjuntos de entrenamiento, validación y prueba, el entrenamiento del modelo, la configuración de los hiperparámetros, el análisis de la importancia de las características (mediante SHAP), la matriz de confusión, y las gráficas de las curvas ROC y Precision-Recall. Estos pasos son fundamentales en el entrenamiento de modelos de Machine Learning, ya que permiten evaluar el rendimiento y la capacidad de generalización del modelo (Chien & Tsai, 2020).
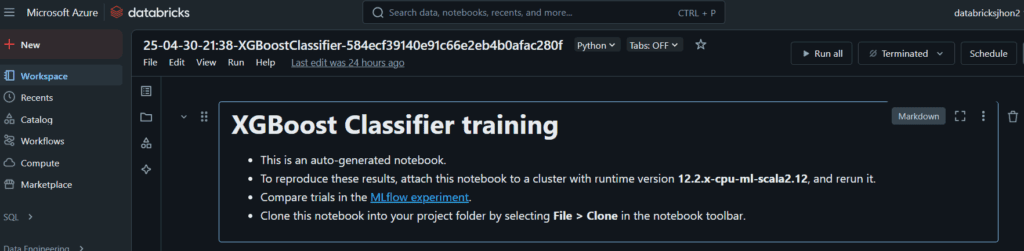
Parte 2: Despliega el Modelo con Models y Serving
Una vez que el modelo ha sido entrenado y evaluado, es hora de desplegarlo para que pueda ser utilizado para realizar predicciones en tiempo real o por lotes. Databricks facilita este proceso mediante el uso de Models y Serving.
2.1 Registro del Modelo
El primer paso para el despliegue es el registro del modelo. En Databricks se puede guardar el modelo en el registro de modelos de MLflow. Este registro permite almacenar las versiones del modelo junto con los metadatos relevantes, como las métricas de evaluación, el tipo de modelo y los hiperparámetros utilizados.
El registro es un paso clave porque te permite gestionar y versionar tus modelos, lo que es esencial cuando se trabaja con modelos en producción. Puedes guardar varias versiones del modelo y actualizarlo conforme a nuevas iteraciones y mejoras.
Para este caso de uso, se ha registrado el modelo XGBoost obtenido en el experimento.

2.2 Predicciones por Lotes
Una vez que el modelo ha sido registrado, puede ser utilizado para realizar predicciones por lotes (batch). Esto significa que es posible pasar grandes cantidades de datos al modelo de una sola vez para obtener predicciones en masa. Databricks facilita la ejecución de inferencias por lotes mediante la integración con Spark, lo que permite procesar grandes volúmenes de datos de manera eficiente.
Este enfoque es adecuado cuando se tienen grandes conjuntos de datos y no es necesario hacer predicciones en tiempo real, pero aún así se necesita una forma eficiente de procesar los datos y obtener resultados rápidos.
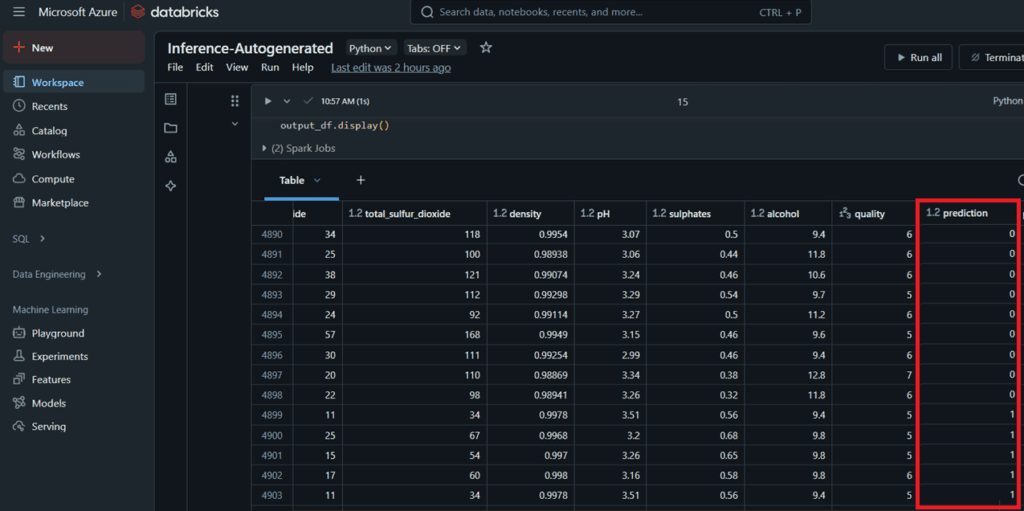
Para este caso de uso, dentro del Módulo de Models de Databricks, se selecciona el modelo registrado y se selecciona la opción User Model For Inference. Luego se selecciona la pestaña Batch Inference, la versión del modelo y el dataset sobre el cual se harán las predicciones.
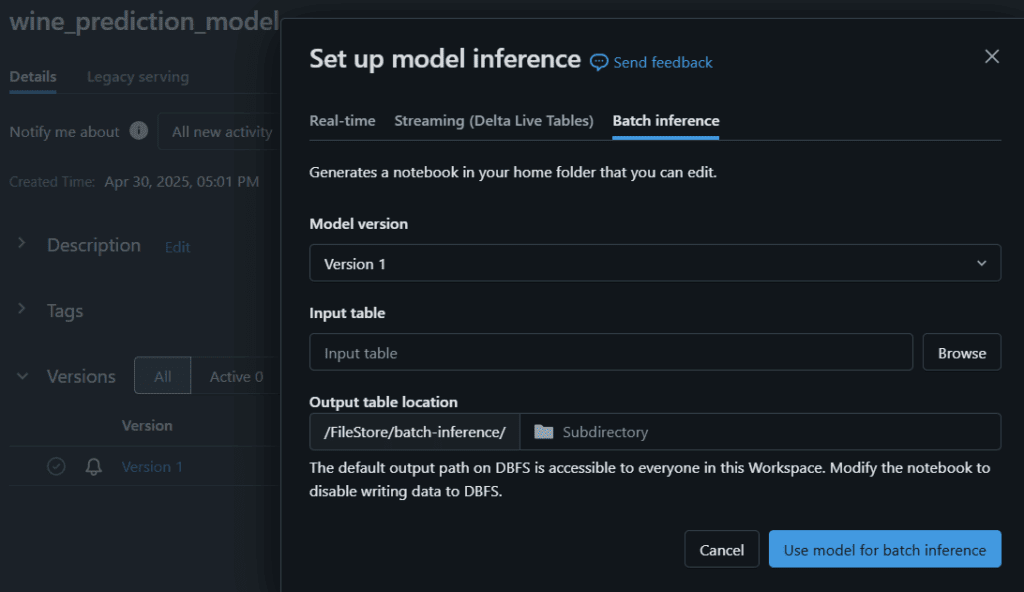
Automáticamente se generará un Notebook que obtendrá la predicción usando el modelo y los datos proporcionados
2.3 Predicciones en Tiempo Real
Si se necesita hacer predicciones en tiempo real, Databricks también permite servir el modelo a través de una API REST. Databricks facilita este proceso mediante la función de Model Serving, que expone el modelo como una API REST. Esto significa que se pueden enviar solicitudes HTTP al modelo, que devolverá predicciones basadas en los datos que se envíen.
Model Serving en Databricks es altamente escalable y puede manejar múltiples solicitudes simultáneas. Es ideal para aplicaciones de producción donde es necesario realizar inferencias rápidas y continuas, como sistemas de recomendación en tiempo real, detección de fraude o personalización de contenido.
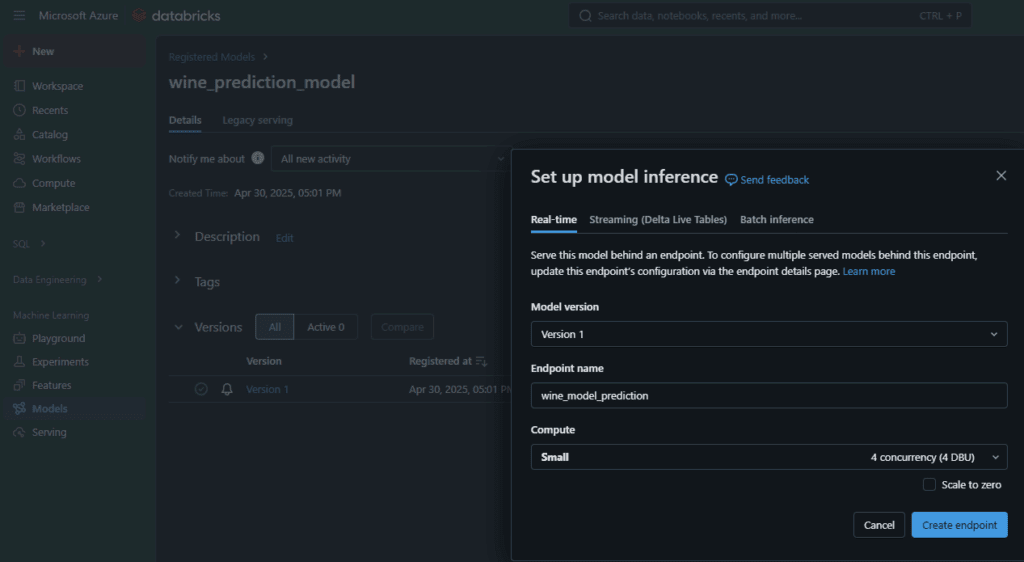
Para este caso de uso, dentro del Módulo de Models de Databricks, se selecciona el modelo registrado y se selecciona la opción User Model For Inference. Luego se selecciona la pestaña Real-time, la versión del modelo y el nombre del tamaño de la máquina que se usará para alojar el modelo. Esta parte solo está disponible para workspaces de Databricks Premium, por lo cual no logró completarse.
Conclusión
Databricks es una plataforma poderosa y versátil para entrenar y desplegar modelos de machine learning. En este blog, hemos cubierto el proceso desde el entrenamiento de un modelo de clasificación utilizando AutoML y Experiments, hasta su despliegue con Model Serving para hacer predicciones en tiempo real y por lotes. Con herramientas como MLflow, AutoML y Spark, Databricks hace que este flujo de trabajo sea rápido, eficiente y fácil de gestionar. Ya sea que estés trabajando con pequeños conjuntos de datos o grandes volúmenes de información, Databricks tiene las capacidades necesarias para hacer que el modelo esté listo para producción en minutos.
Referencias
Behrens, J. T. (2003). Exploratory Data Analysis. In Major Reference Works. Wiley Online Library.
Chien, S., & Tsai, M. (2020). Machine learning: Concepts, algorithms, and applications. Springer. https://doi.org/10.1007/978-3-030-38867-6
Databricks. (2025a). MLflow: Gestiona el ciclo de vida completo de modelos de machine learning. Recuperado el 15 de mayo de 2025, de https://www.databricks.com/product/mlflow
Databricks. (2025b). AutoML: Automatización del entrenamiento de modelos de machine learning. Recuperado el 15 de mayo de 2025, de https://www.databricks.com/product/automl
Powers, D. M. W. (2011). Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation. Journal of Machine Learning Technologies, 2(1), 37–63.
Julián Felipe Parra
Technical Specialist
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
Te puede interesar





Footer



© 2025 Bluetab Solutions Group, SL. All rights reserved.