

AWS Solutions Architect
Senior Data Architect

En esta segunda entrega nos centraremos en analizar los diferentes servicios que ofrece Databricks para asegurar el escalado de nuestros servicios y la recuperación ante fallas del sistema, así como otros aspectos relativos a la seguridad como encriptación de los datos tanto reposo como en tránsito.
Primera entrega (link):
Segunda entrega:
Entendemos por Disaster Recovery al conjunto de políticas, herramientas y procedimientos que permiten la recuperación de la infraestructura cuando el sistema en su conjunto cae, como por ejemplo una caída de una región de Azure.
No debemos confundir estas políticas y herramientas con las empleadas en materia de alta disponibilidad de nuestro sistema (mínimo nivel de servicios).
Para ello, cuando implementamos una solución en la nube, una de las principales preguntas que debemos plantearnos a la hora de diseñar e implementar nuestra solución es:
Dar respuesta a estas preguntas es de vital importancia si deseamos que nuestra solución pueda cumplir adecuadamente el estándar de calidad que hayamos planteado.
Para este punto debemos analizar en que ámbito de nuestra solución opera Databricks y que herramientas o pautas debemos seguir para que la plataforma pueda cumplir con su servicio.
Debemos recordar que Databricks ofrece soluciones en materia de transformación y almacenamiento de datos tanto batch como en streaming, utilizando Azure Blob storage como capa de persistencia de datos no estructurados, como asimismo diferentes herramientas relacionadas con orquestación de jobs o análisis ad-hoc de datos vía SQL como servicio de analitica. Por lo tanto en este punto veremos que diferentes herramientas pueden ser propuestas para sincronizar nuestros workspaces,activos/recursos involucrados entre nuestras regiones.
Para poder comprender que es Disaster Recovery, deberemos primero comprender dos conceptos importantes:
Hace referencia a la cantidad de datos máxima pérdida (medida en minutos) aceptable después de una caída del sistema. En este caso al disponer de Azure Blob Storage como sistema de persistencia distribuido, el concepto aplicaría a los datos de usuario temporales almacenados por Databricks, como por ejemplo cambios realizados en nuestros notebooks.
Entendemos por RTO al periodo de tiempo desde la caída del sistema hasta la recuperación del nivel de servicio marcado.
En la siguiente imagen, podemos observar ambos conceptos de una forma visual:
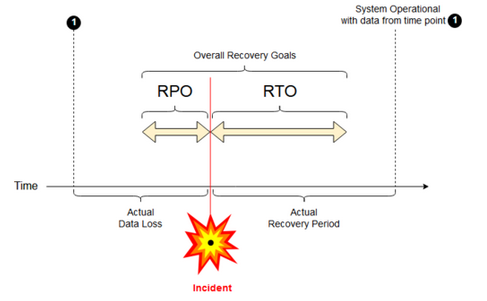
Es importante indicar que la corrupción existente en los datos no se verá mitigada por las políticas asociadas a DR, sin embargo Databricks ofrece Delta time travel como sistema de versionado.
Una vez comprendido los conceptos de RPO y RTO, deberemos comprender los diferentes tipos de regiones en los que operará nuestra solución:
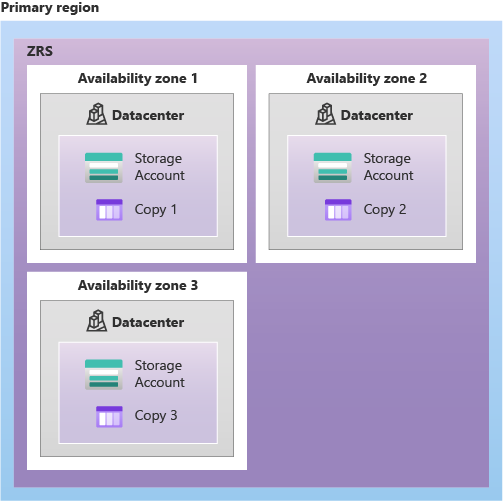
En nuestro caso de uso, estamos implementando un workspace de Databricks, por lo tanto emplearemos como capa de persistencia principal Blob Storage. Este servicio ofrece diferentes posibilidades a la hora de replicar nuestros datos entre regiones, vamos a verlas.
Region primaria

Region primaria y secundaria
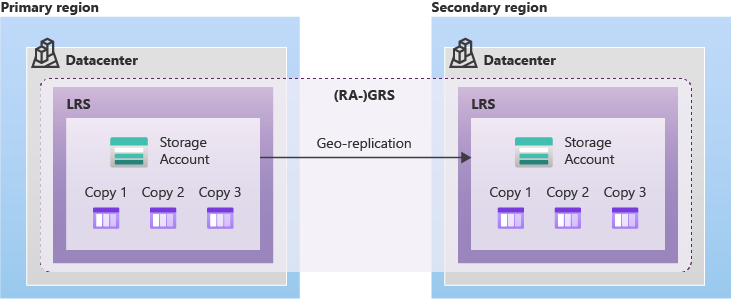
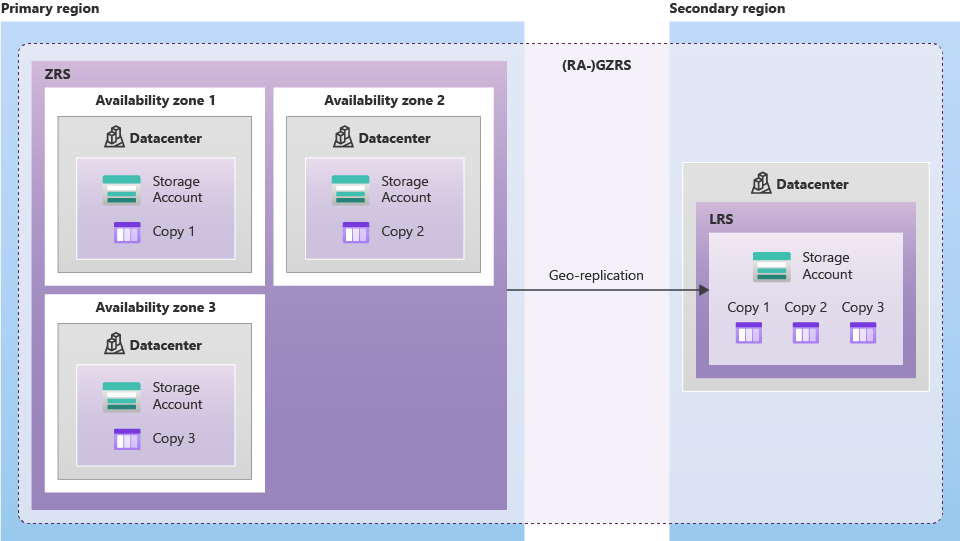
En ambos casos, el acceso a los datos en la región secundaria no estará disponible salvo activación de la opción de lectura RA.
Dadas estas configuraciones, en la siguiente imagen se pueden ver los escenarios planteados en los que nuestros datos dejarían de ser accesibles.
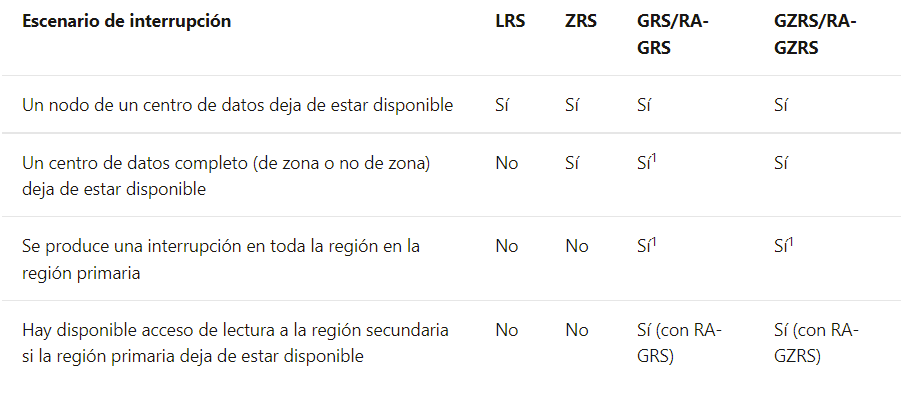
Deberemos configurar el nivel de replicación y redundancia entre zonas con el fin de disponer de nuestros datos sincronizados y disponibles en las regiones secundarias con el fin de que estás puedan estar operativas.
Dentro de los tipos de despliegue, podemos encontrar diferentes combinaciones según la necesidad de respuesta y los costes que deseamos asumir por su disponibilidad.
Es posible encontrar combinaciones de estos: activo-pasivo, activo-activo. De forma general:
Backup Restore
Es la estrategia más económica y lenta que podemos implementar. El objetivo principal es tener un conjunto de puntos de restauración en ambas regiones que podamos emplear para recuperar el servicio, sin necesidad de aprovisionar elementos core del sistema en otras regiones.
Pilot Light
Las piezas más importantes de nuestro sistema se encuentran desplegadas de forma activa pero bajo mínimos dentro de nuestra región secundaria, de forma que ante una caída del sistema los servicios principales podrían estar operativos y podrían escalarse de forma gradual (activo-pasivo).
Warn Standby
Estaríamos en un escenario muy similar a Pilot Light pero donde no solo tendríamos activos nuestros sistemas principales sino también una buena parte de los secundarios funcionando bajo mínimos pero listos para ser escalados (activo-pasivo).
Multi-site
Este plan ofrece el mayor grado de respuesta ya que implica disponer de forma activa todas nuestras piezas en una región secundaria, listas para dar servicio en caso de caída de la región principal (activo-activo)
Deberemos elegir la estrategia que mejor se adapte a nuestro caso de uso que dependerá principalmente del nivel de respuesta y coste asumible.
Dentro de los diferentes procedimientos, encontramos la estrategia activa-pasiva como la solución más sencilla y barata pero a la vez efectiva a la hora de ofrecer respuesta y servicio en el caso donde tras una caída del sistema en la región principal, el sistema pasivo entra en funcionamiento dando soporte al servicio.
La estrategia podría ser implementada de forma unificada para toda la organización o por grupos/departamentos de forma independiente basados en sus propias reglas y procedimientos.
De una forma global nos encontraremos que el procedimientos típico a alto nivel sería el siguiente:
Una vez nos hacemos una idea general de como sería un workflow típico de recuperación activo-pasivo, estudiaremos como podemos aplicarlo dentro de Databricks en nuestros workspaces.
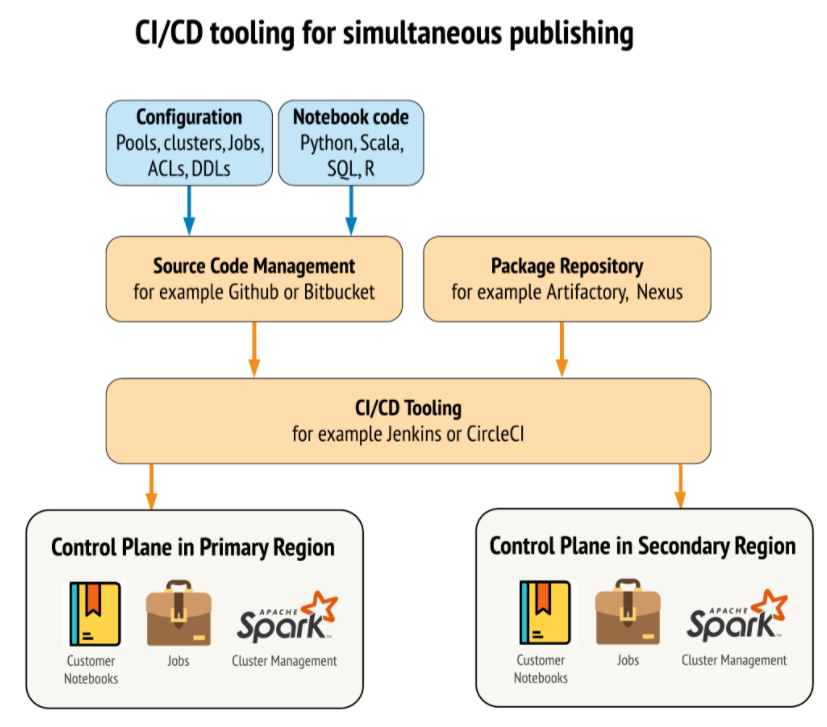
Databricks como plataforma de Data Analytics, tiene los datos como principal activo. Por ello se deben de definir las estrategias que permitan no solo poder seguir operando los servicios de la plataforma y workflows productivos en la región de soporte, sino la estrategia que permita generar consistencia en la propia replicación de los diferentes data sources.
En la siguiente imagen se especifican a modo de diagrama los diferentes activos que se verían involucrados en la replicación del plano de control o de datos.
Una vez realizado un análisis de nuestro sistema, deberemos analizar pieza por pieza como podemos realizar el procedimiento de réplica y sincronización.
Existen dos principales estrategias:
Databricks ofrece en la siguiente tabla un resumen del conjunto de estrategias que se podrían aplicar según el recurso/activo involucrado de nuestro workspace.
Es importante señalar que a día de hoy no hay ningún servicio oficial por parte de Databricks que permita administrar e implementar una política activa-pasiva de los workspaces en Azure.
| Herramientas de replicación | |||
|---|---|---|---|
| FEATURE | Sync Client | CI/CD | |
| Código fuente, notebooks, librerías | Sincronización con la región secundaria | Despliegue en ambas regiones | |
| Usuarios y grupos | Empleo SCIM para la sincronización en ambas regiones | Control de los metadatos de los usuarios y grupos a través de GIT. | |
| Configuración de los pools | Empleo del CLI o API para la creación en la segunda región | Empleo de templates. Configurar la región secundara con min_idle_instances a 0 | |
| Configuración de los jobs | Empleo del CLI o API para la sincronización con la segunda región | Empleo de templates. Configurar la región secundaria con concurrencia a 0 | |
| ACLs | Mediante la API de Permisos 2.0 es posible replicar los controles de acceso sobre los recursos copiados | Empleo de templates. | |
| Librerias | DBFS | Repositorio central | |
| Scripts de inicialización del cluster | Replicar de una región a otra a través del almacenamiento en el workspace | Repositorio central | |
| Metadata | | Incluir las DDL en el código fuente. | |
| Secretos | Replicacion via API o CLI en el momento de creación | ||
| Configuraciones del cluster | Replicacion via API o CLI en el momento de creación | Empleo de templates en GIT. | |
| Permisos de Notebooks, jobs y directorios | Replicación mediante la API de Permisos 2.0 | Empleo de templates en GIT. | |
Una vez, tenemos clara nuestra estrategia deberemos estudiar como podemos implementarla, para ello disponemos un conjunto de herramientas que van desde IaC, librerías de sincronización de data sources y migración de workspaces. Sin embargo, ninguna de las librerías de sincronizado/migración es oficial y aún se encuentran en desarrollo.
En este punto, veremos las diferentes opciones que ofrece Databricks en materia de escalabilidad, debido a que este punto ya ha sido tratado profundamente por nuestros compañeros dentro de la entrada Databricks sobre AWS – Una perspectiva de arquitectura (parte 2), nos limitaremos a comentar las características equivalentes en Azure.
De la misma forma que en AWS, Databricks ofrece sobre Azure la posibilidad de escalar horizontalmente de una forma dinámica el número de workers dependiendo el mínimo y máximo que hayamos definido, permitiendo mejorar el tiempo de los trabajos sin sobre asignar recursos y por lo tanto reduciendo el coste global por trabajo en hasta un 30%.
Por lo general, en la forma tradicional cuando se definían las políticas de escalado para nuestros clusters se tenían que establecer una serie de umbrales estáticos donde si estos son rebasados se aprovisionan recursos extra, en forma de nodos de cómputo de bajo coste y efímeros (Spot). En muchos casos el escalado in/out de estos recursos no es lo suficientemente rápido, generando una ralentización global del job y una utilización subóptima de los recursos.
Para ello Databricks propone un nuevo tipo de escalado optimizado [6], donde a partir de la información de los ejecutores es capaz de adaptar rápidamente los recursos del trabajo a sus necesidades de una forma rápida y eficiente, sin necesidad de esperar a que el trabajo completo termine para comenzar el desescalado.
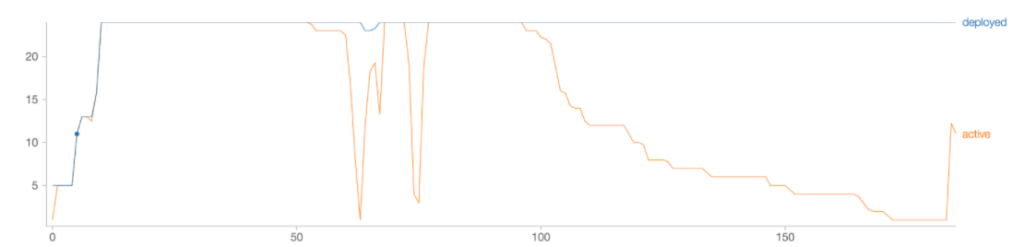
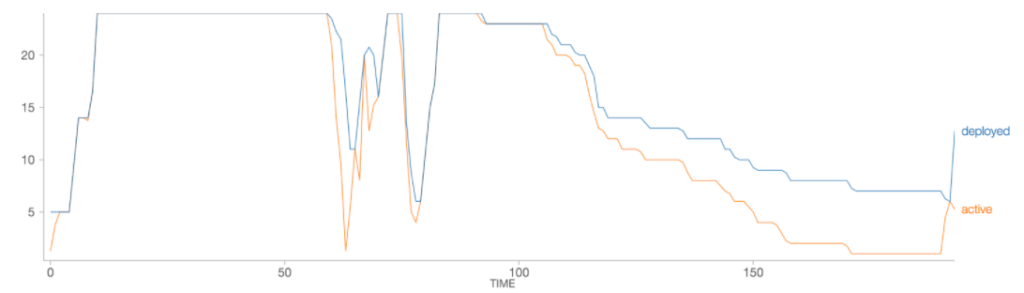
Caracteristicas:
Para reducir al máximo el tiempo de lanzamiento de una nueva instancia, Databricks permite mantener un set de clusters o pool pre-inicializado en estado idle listo para su empleo en nuestros trabajos o en los procesos de escalado. Si se llega al caso de que todo el pool de instancias se ha consumido, de forma automática se asignarán nuevas instancias al pool.
De la misma forma al escalado de los clusters, podremos definir un número máximo y mínimo de instancias que el pool podrá tener en estado idle para su posterior asignación al trabajo demandante y el tiempo que estas pueden permanecer desasignadas hasta su eliminación.
Respecto al tipo de instancias asignado al pool, no podrán cambiarse, tanto el driver como los workers del trabajo consumirán el mismo tipo de instancias.
Databricks ofrece la posibilidad de asignar un auto escalado en el almacenamiento local en disco del cluster con el fin de acotar la necesidad de dimensionado de estos.
Databricks monitoriza el espacio libre en el disco de forma que en caso necesario se montará un disco externo sobre éste. Es importante señalar que estos discos una vez asignados no podrán desmontarse hasta que el cluster no sea eliminado, por ello se recomienda emplearlos en instancias Spot o que en instancias tengan una política de auto finalizado
Uno de los aspectos más importantes cuando vamos a seleccionar una plataforma para el tratamiento de datos es la seguridad de los mismos. Debe ofrecer mecanismos de encriptación de datos tanto en los sistemas de almacenamiento, comúnmente conocido como datos en reposo (at rest), como cuando están en movimiento (in-transit).
Databricks encripta todos los datos que circulan por cada uno de sus diferentes componentes y orígenes con TLS. Además de la encriptación de datos, se encriptan con TLS todas las comunicaciones que se realizan entre el plano de control y el plano de datos, por tanto los comandos, consultas y meta-data viajan también encriptados.
Para plataformas que requieran un nivel alto de protección, se puede realizar la encriptación entre los nodos del cluster utilizando la encriptación RPC de Spark [7]. Está se realiza con cifrado AES de 128 bits a través de una conexión TLS 1.2. Está opción solo está disponible con el plan premiun y es necesario establecer los parámetros de configuración de Spark en el script de init del cluster o en el global si necesitamos que se aplique a todos los cluster del workspace. Es importante que tengamos en cuenta que la encriptación entre los nodos del cluster puede suponer una disminución en el rendimiento de los procesos y dado que la red privada de los nodos suele estar aislada, en la mayoría de los casos no será necesario este tipo de encriptación.
Para el cifrado de los datos en reposo se utiliza SSE [8] (server-side encryption), cifra automáticamente los datos cuando se guardan en el almacenamiento distribuido (blob storage, ADLS y ADLS2).
Por defecto DBFS está encriptado usando claves administradas por Microsoft pero también permite la opción de usar claves administradas por el cliente, comúnmente conocidas como (CMK), permitiendo de este modo utilizar tu propia clave de cifrado para cifrar la cuenta de almacenamiento del DBFS. Además, tanto si se usa clave administradas como tu propia clave, también se ofrece la posibilidad de una capa adicional de cifrado utilizando un algoritmo/modo de cifrado diferente en la capa de infraestructura utilizando claves de cifrado administradas por la plataforma.
Para tener un completo cifrado de los datos en reposo, además del cifrado datos en el almacenamiento distribuido, se puede habilitar la encriptación de los disco locales de los nodos del clúster con lo que se permite la encriptación de los datos temporales que se guardan en las ejecuciones de los procesos. Actualmente está característica se encuentra en en versión preliminar pública y sólo está disponible para la creación del cluster desde el api REST utilizando la configuración siguiente:
{"enable_local_disk_encryption": true} También hay que tener en cuenta que activar esta opción puede suponer cierto impacto en el rendimiento de los procesos.
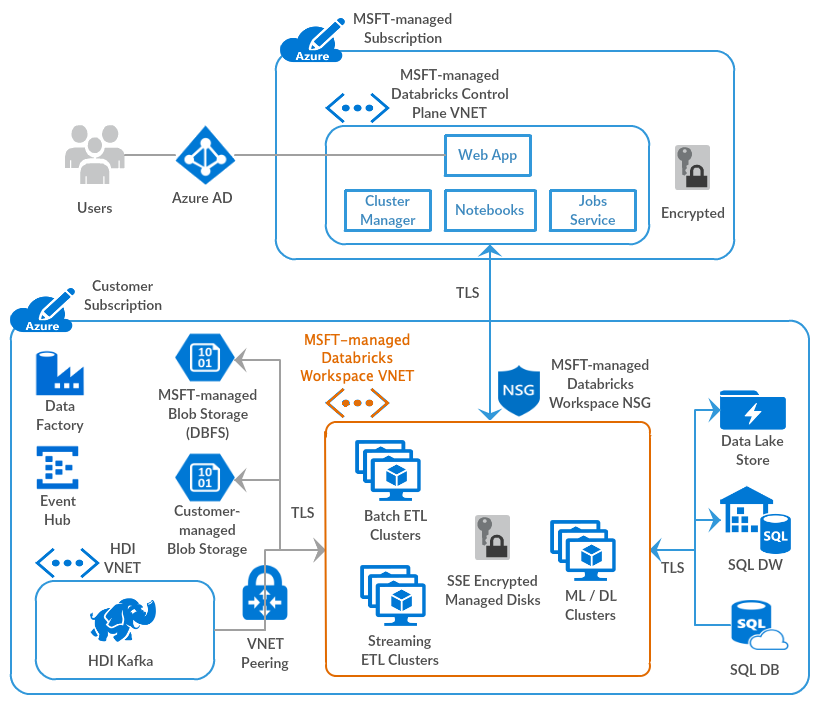
Para el correcto gobierno de una plataforma de ejecución de datos es necesario disponer de las herramientas necesarias para poder realizar el seguimiento y comprobación de ejecución de los workloads. Databricks integra en su plataforma todos elementos necesarios para realizar el mismo en un entorno de Spark. A continuación, vamos a resumir las opciones que integra Databricks out of the box aunque se pueden realizar monitorizaciones más avanzadas utilizando otras herramientas o servicios.
Para cada uno de los cluster o job cluster creados en la plataforma podemos consultar de forma visual:
Event log: Se muestran todos los eventos relacionados con el ciclo de vida del cluster que han sucedido, como pueden ser, creación, terminación, cambios en la configuración…
Spark UI: Permite el acceso a la GUI ofrecida por Spark. Esta GUI es fundamental para poder detectar y solventar los problemas de performance en las aplicaciones de Spark.
Driver Logs : Permite ver los logs de ejecución tanto de la salida estándar , error y log4j. Databricks también permite que se realice el volcado de logs en un filesystem determinado, para ellos es necesario configurarlo en las opciones avanzadas del cluster o indicándolo en la creación del cluster si se realiza desde crea desde API o CLI.
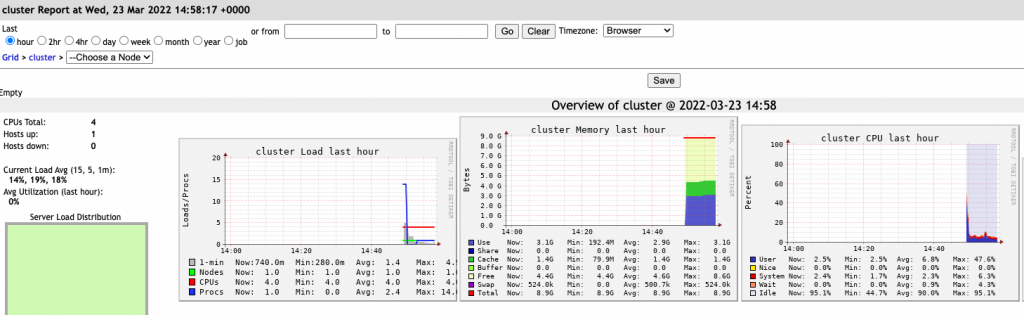
Metrics: Databricks proporciona acceso a Ganglia Metrics para obtener un mayor detalle del rendimiento que está ofreciendo el cluster
Azure Databricks nos ofrece la posibilidad de descargar los registros de las actividades realizadas por los usuarios a través del registro de diagnóstico [9]. Activando esta opción se enviarán los registros de la actividad de usuario a un destino seleccionado, Azure tiene disponibles 3 opciones para el envío de los registros: Cuenta de Almacenamiento, Event y Log Analytics.
Estos son los servicios que se pueden seleccionar para obtener registros de diagnóstico.
| SERVICIOS DISPONIBLES PARA DIAGNÓSTICO | ||
|---|---|---|
| DBFS | sqlanalytics | modelRegistry |
| clusters | genie | repos |
| accounts | globalInitScripts | unityCatalog |
| jobs | iamRole | instancePools |
| notebook | mlflowExperiment | deltaPipelines |
| ssh | featureStore | sqlPermissions |
| workspace | RemoteHistoryService | databrickssql |
| secrets | mlflowAcledArtifact | |
La activación se puede realizar desde Azure Portal, API REST, CLI, ó powershell. Los registros están disponibles en un plazo de 15 minutos después de la activación.
Este sería el esquema de un registro de diagnóstico de salida
| Campo | Descripción | ||
|---|---|---|---|
| operationversion | Versión del esquema del formato del registro de diagnóstico. | ||
| time | Marca de tiempo UTC de la acción. | ||
| properties.sourceIPAddress | Dirección IP de la solicitud de origen. | ||
| properties.userAgent | Explorador o cliente de API usado para realizar la solicitud. | ||
| properties.sessionId | Identificador de sesión de la acción. | ||
| identities | Información sobre el usuario que realiza las solicitudes: | ||
| category | Servicio que registró la solicitud. | ||
| operationName | La acción, como el inicio de sesión, el cierre de sesión, la lectura, la escritura, etc. | ||
| properties.requestId | Identificador de solicitud único. | ||
| properties.requestParams | Pares clave-valor de parámetro usados en el evento. El requestParams campo está sujeto a truncamiento. Si el tamaño de su representación JSON supera los 100 KB, los valores se truncan … truncated y la cadena se anexa a las entradas truncadas. En raras ocasiones, cuando un mapa truncado sigue siendo mayor que 100 KB, TRUNCATED en su lugar hay una sola clave con un valor vacío. | ||
| properties.response | Respuesta a la solicitud: * * : mensaje de error si se ha producido un error. * * : resultado de la solicitud. * * : código de estado HTTP que indica si la solicitud se realiza correctamente o no. | ||
| properties.logId | Identificador único de los mensa jes de registro. | ||
Tabla Esquema Registro Salida (fuente: Azure)
Para la explotación de los registros, si se ha seleccionado la opción de Logs Analytics, podremos explotarlos de forma sencilla utilizando Azure Monitor. Pero si lo que se desea es explotar estos registros con cualquier otra plataforma, servicio o herramienta es posible tomando estos registros JSON del lugar del envio seleccionando en la activación.
[1] Databricks Terraform Provider. [link]
[2] Databricks Workspace Migration Tools. [link]
[3] Databricks Sync. [link]
[4] Databricks Disaster Recovery [link]
[5] Cifrado entre nodos de trabajo[link]
[6] Optimized AutoScaling [link]
[7] Spark Security [link]
[8] Azure encriptación discos [link]
[9] Registro de diagnostico [link]
AWS Solutions Architect
Senior Data Architect
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar




