Databricks sobre Azure – Una perspectiva de Arquitectura (parte 1)

Databricks sobre Azure – Una perspectiva de arquitectura (parte 1)
Compartir en twitter
Compartir en linkedin

Gabriel Gallardo Ruiz
Senior Data Architect
Databricks tiene como objetivo dotar de un entorno intuitivo al usuario no especializado para que pueda desarrollar las diferentes funciones en materia de ingeniería y ciencia de datos, dotando además de una capa de gobierno y gestión del dato.
Nuestro objetivo con este artículo, no es tanto describir y analizar cómo emplear estas herramientas, sino ver como son integradas desde un punto de vista de arquitectura dentro del proveedor de Azure.
Databricks como solución Lakehouse
La plataforma Databricks sigue el paradigma de Lakehouse, en el que se combinan las bondades del Data Warehouse con las del Data Lake, permitiendo tener un buen rendimiento tanto en sus consultas analiticas gracias a la indexacion, como transaccionalidad a través de Delta Lake, sin perder la flexibilidad de una arquitectura de datos abierta y escalable, junto a una mejor gobernanza del dato y del acceso a los recursos y servicios del lago, permitiendo de una forma general disponer de una arquitectura menos compleja y más integrada.
Este artículo se dividirá en dos entregas.
- La primera, tendrá como objetivo explicar cómo Databricks organiza y despliega su producto en Azure, así como las diferentes configuraciones en materia de comunicación/seguridad entre Databricks y otros servicios de Azure.
- La segunda, estará centrada en la capa de seguridad del dato y escalabilidad de la infraestructura así como monitorización, despliegue y recuperación ante errores.
Primera entrega:
- Arquitectura alto nivel
- Planes y tipos de carga de trabajo
- Networking
- Identidad y Gestión de accesos
Segunda entrega (próximamente):
- DR
- Cifrado
- Escalabilidad
- Logging y monitorización
- Despliegue
Glosario
- Azure Data Lake: Permite almacenar múltiples formatos de datos en un mismo lugar para su explotación y análisis, actualmente Azure dispone la versión Gen2 .
- All Purpose Compute: Diseñado para entornos colaborativos en los que se recurra de forma simultánea al clúster por parte de Data Engineers y Data Scientist.
- Azure Key Vault: Servicio administrado de Azure que permite el almacenamiento seguro de secretos.
- Azure Virtual Network (VNET): Red virtual aislada lógicamente en Azure.
- Continuous integration and continuous delivery CI/CD: Conjunto de herramientas y pautas automatizadas que permiten aplicar una integración y puesta en producción continua
- Data Lake: Paradigma de almacenamiento distribuido de datos provenientes de multitud de fuentes y formatos, estructurados, semi estructurados y sin estructurar.
- Identity Provider (IdP): Entidad que mantiene la información de identidad de los individuos dentro de una organización.
- Jobs Compute: Enfocado a procesos orquestados mediante pipelines gestionados por data engineers que puedan conllevar autoescalado en ciertas tareas
- Jobs Light Compute: Diseñado para procesos cuya consecución no sea crítica y no conlleve una carga computacional muy elevada.
- Network Security Group o NSG: Especifican las reglas que regulan el tráfico de entrada y salida de la red y los clusters en Azure.
- Notebook: Interfaz web para ejecutar código en un cluster, abstrayendo del acceso al mismo.
- PrivateLink: Permite el acceso privado (IP privada) a Azure PaaS a través de la VNET del usuario, de la misma forma que los service endpoints el tráfico se enruta a través del backbone de Azure.
- Azure role-based access control (RBAC): Sistema de autorización integrado en Azure Resource Manager que permite asignar permisos granulares sobre recursos a usuarios de Azure.
- Security Assertion Markup Language (SAML): Estándar abierto utilizado para la autenticación. Basado en XML, las aplicaciones web utilizan SAML para transferir datos de autenticación entre dos entidades, el Identity Provider y el servicio en cuestión.
- Secure Cluster Connectivity (SCC): Comunicación a través de túnel inverso SSH entre Control Plane y cluster. Permite no tener puertos abiertos ni IPs públicas en las instancias.
- Service Endpoints: Componente de red que permite conectar una VNET con los diferentes servicios dentro de Azure a través de la propia red de Azure.
- Service Principal: Entidad creada para que la administración y gestión de tareas que no queden asociadas a un miembro de la organización en particular si no a un servicio
- Secret Scope: Colección de secretos identificados por un nombre.
- Single Sign On (SSO): Permite a los usuarios la autenticación a través de un Identity Provider (IdP) proporcionado por la organización, requiriendo de compatibilidad con SAML 2.0.
- Workspace: Entorno compartido para acceder a todos los activos de Databricks. En este se organizan los diferentes objetos (notebooks, librerias, etc…) en carpetas y se administran los accesos a recursos computacionales como clusters y jobs.
Arquitectura
Databricks como producto
Databricks permanece integrado dentro de Azure como servicio propio a diferencia de otros proveedores, permitiendo el despliegue de una forma más directa y sencilla ya sea desde la propia consola o mediante templates.
Dentro de los servicios ofrecidos por Databricks destacan:
- Databricks SQL: ofrece una plataforma para realizar consultas SQL ad-hoc contra el Data Lake, así como múltiples visualizaciones de los datos con dashboards.
- Databricks Data Science & Engineering: proporciona un workspace que permite la colaboración entre diferentes roles (ingenieros de datos, científicos de datos, etc) para el desarrollo de diferentes pipelines para la ingesta y explotación del Data Lake.
- Databricks Machine Learning: ofrece un entorno para el desarrollo y explotación de modelos de machine learning end-to-end.
Además Databricks ofrece Spark como framework de programación distribuida, así como integración con Delta Lake y soporte a transacciones ACID para datos estructurados y no estructurados, unificación de fuentes batch y streaming.
Databricks ofrece también una solución en material de orquestación y despliegue de jobs de una forma productiva, permitiendo además paralelismo entre ellos, hasta 1000 de forma concurrente. Pudiendo emplearse solo dentro del workspace de Data Science & Engineering
Dentro de las ventajas añadidas ofrecidas por Databricks se encuentra el empleo de Databricks File System (DBFS), se trata de un sistema de ficheros distribuido de acceso para los clusters.
- Permite montar puntos de almacenamiento para acceder a los objetos sin necesidad de credenciales específicos para su uso.
- Evita la necesidad de emplear urls para acceder a los objetos, facilitando el acceso vía directorios y semántica.
- Otorga una capa de persistencia al almacenar en el file system los datos, evitando que estos se pierdan cuando el cluster es finalizado.
Databricks Repos: ofrece integración y sincronización con repositorios GIT, incluyendo una API para el empleo de pipelines de CI/CD. Los proveedores Git actuales incluidos son:
- GitHub
- Bitbucket
- GitLab
- Azure DevOps
Overview de la arquitectura
En esta sección analizaremos cómo se realiza el despliegue de Databricks dentro de la cuenta del cliente en su proveedor cloud, este caso Azure.
Databricks se compone principalmente de dos capas; una de control (interna) y otra de datos (externa/cliente).
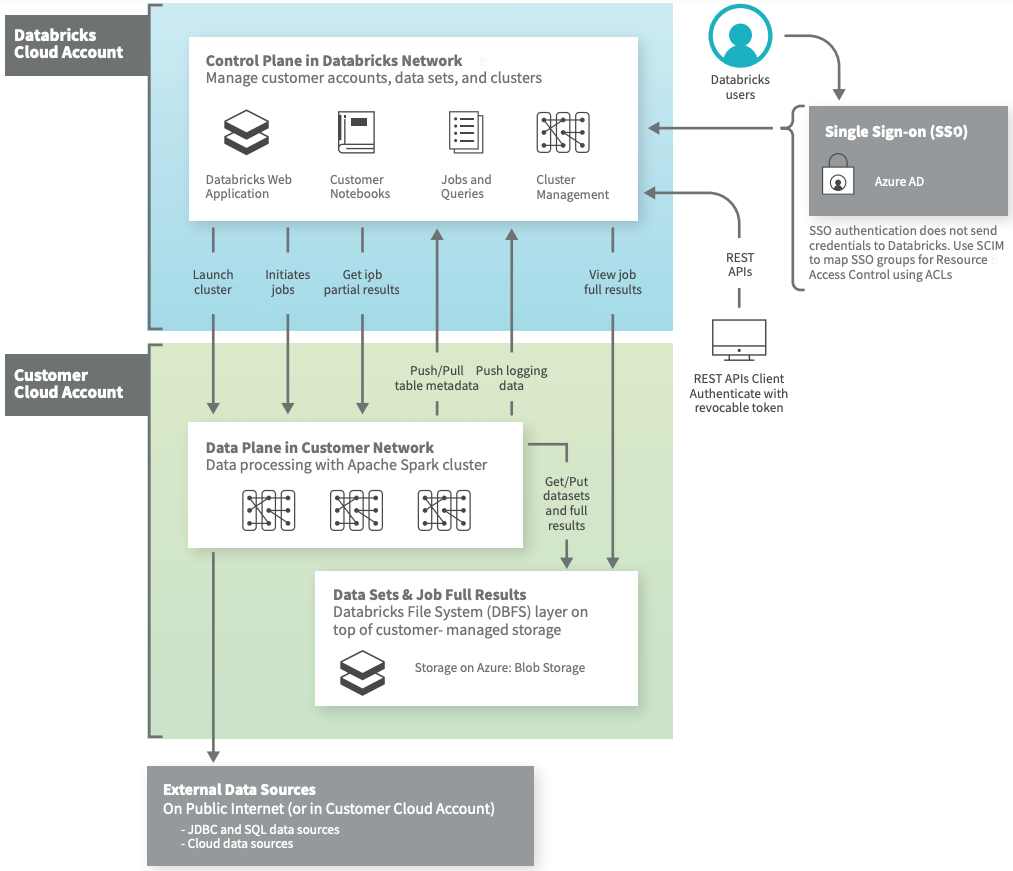
En la imagen anterior podemos ver como la capa de control permanece en la suscripción de databricks, bajo su control, diseño y administración interna siendo compartida esta por todos los usuarios.
Los principales servicios contenidos, son:
- Notebooks: Todos los notebook, resultados y configuraciones permanecen encriptados
- Job Scheduler
- Rest API
- Metastore: Hive metastore gestionado por databricks
- Cluster manager: Solicita máquinas virtuales para los clúster que se lanzarán en el plano de datos
La capa de datos se encuentra dentro de la suscripción del cliente y por lo tanto será administrada por él. En esta capa encontramos los jobs y clusters empleados para la ejecución de las ETLs, así como los datos empleados en ellas.
Es importante señalar que Databricks disponibiliza dos interfaces de red en cada nodo desplegado, en una de ellas se direccionara el tráfico hacia el plano de control y en la otra el tráfico interno entre nodos (driver – ejecutores)
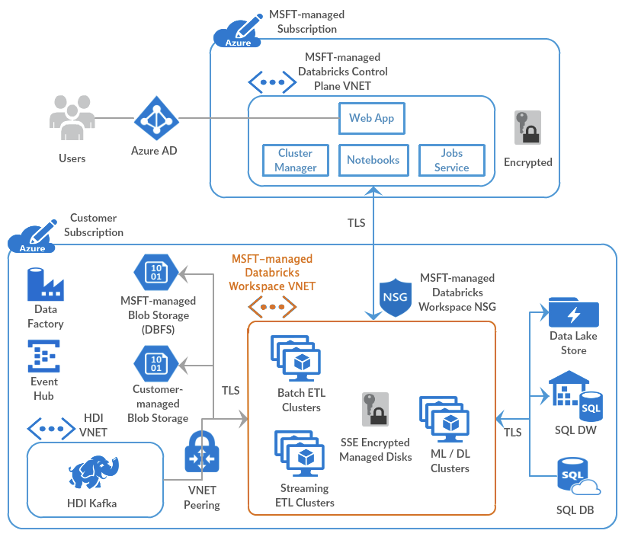
Databricks ofrece dos métodos principales para realizar el despliegue del plano de datos y que posteriormente comentaremos en profundidad:
- Por un lado tenemos Databricks managed VNET, siendo este el despliegue dado por defecto donde Databricks se encarga de desplegar los recursos necesarios dentro de la cuenta del cliente.
- Por otro lado tenemos un segundo tipo de despliegue Databricks VNET injection donde es el cliente el que disponibiliza los recursos mínimos necesarios para el correcto funcionamiento y comunicación contra el control-plane.
En ambos casos, la topología de red en el Data Plane se compondrá de dos subredes.
- Container subnet o “private” subnet
- Host subnet or “public” subnet
Planes y tipos de carga de trabajo
Además del coste de la infraestructura empleada para el procesamiento y el almacenamiento en Azure, Databricks añade un sobrecargo extra expresado en DBU (unidades de procesamiento) en función del tipo de instancia levantada y su tamaño, así como el tipo de workload empleado.
Se distinguen 2 tipos principales:
- Jobs Cluster: Ejecución de pipelines programadas no iterativas, distinguiéndose según el tamaño del cluster aprovisionado en ligero o normal. Los jobs suelen emplearse creando clusters efímeros y siendo eliminados después de la ejecución de los mismos.
- All purpose: Clusters empleados para trabajar de forma iterativa (MANDATORY) permitiendo ejecutar y desarrollar diferentes notebooks concurrentemente.
Además, según el tipo de cuenta contratada Standard o Premium se realizarán cargos adicionales sobre el coste de la DBU.
| AZURE PLAN | ||
|---|---|---|
| Standard | Premium | |
| One platform for your data analytics and ML workloads | Data analytics and ML at scale across your business | |
| Job Light Compute | $0,07/DBU | $0,22/DBU |
| Job Compute | $0,15/DBU | $0,30/DBU |
| SQL Compute | N/A | $0,22/DBU |
| All-Purpose Compute | $0,40/DBU | $0,55/DBU |
Coste imputado por DBU respecto a los factores computacionales y arquitectónicos
| WORKLOAD TYPE (STANDARD TIER) | |||
|---|---|---|---|
| FEATURE | Jobs Light Comput | Jobs compute | All-purpose compute |
| Managed Apache Spark | |||
| Job scheduling with libraries | |||
| Job scheduling with notebooks | |||
| Autopilot clusters | |||
| Databricks Runtime for ML | |||
| Managed MLflow | |||
| Delta Lake with Delta Engine | |||
| Interactive clusters | |||
| Notebooks and collaboration | |||
| Ecosystem integrations | |||
Características por tipo de carga de trabajo plan Standard
| WORKLOAD TYPE (STANDARD TIER) | |||
|---|---|---|---|
| FEATURE | Jobs Light Comput | Jobs compute | All-purpose compute |
|
Role Based Access Control for clusters, jobs, notebooks and tables |
|||
| JDBC/ODBC Endpoints Authentication | |||
| Audit Logs | |||
| All Standard Plan Features | |||
| Azure AD credential passthrough | |||
| Conditional Authentication | |||
| Cluster Policies | |||
| IP Access List | |||
| Token Management API | |||
Características por tipo de carga de trabajo plan Premium
Es importante señalar que además podrán obtenerse descuentos de hasta el 37% en los precios por DBU, realizando compras aprovisionadas de estas (DBCU o Databricks Commit Units) para 1 o 3 años.
Networking
En este apartado explicaremos los dos diferentes tipos de despliegue ya comentados anteriormente y sus peculiaridades en materia de conexión y acceso al plano de control, así como al control del tráfico entrante/saliente.
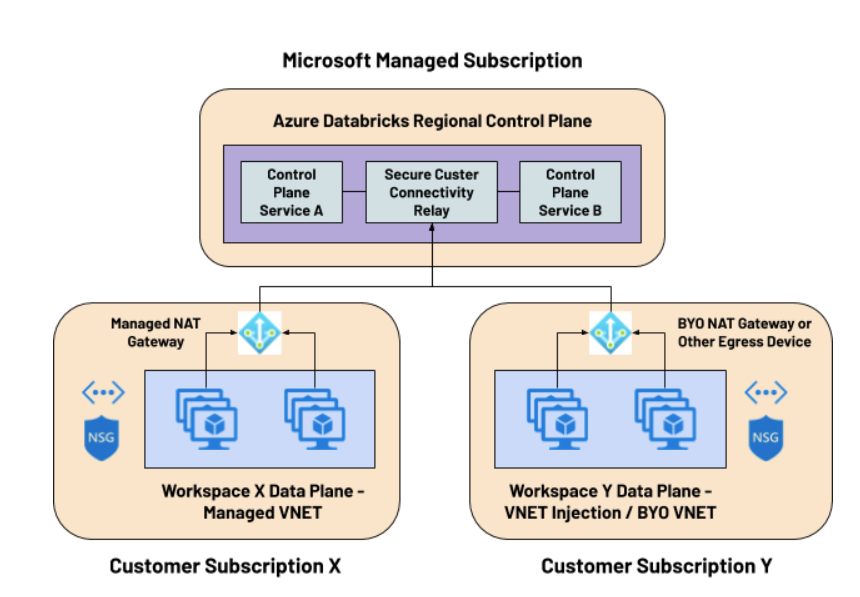
Red administrada por Databricks
En esta alternativa, Azure permite a Databricks desplegar el plano de datos sobre nuestra suscripción, disponibilizando los recursos que permitirán la conexión contra el plano de control y el despliegue de jobs, clusters y otros recursos.
- La comunicación entre el plano de datos y plano de control independientemente de tener activado Secure Cluster Connectivity (SCC) se realizará por el backbone interno de Azure, sin enrutar tráfico sobre la red pública.
- Secure Cluster Connectivity (SCC) podrá ser activado para poder trabajar sin IPs públicas.
- El tráfico inbound/outbound de los clusters estará controlado mediante diferentes reglas por el network security group NSG que no podrán ser modificables por el usuario.
Red administrada por el cliente (VNET injection) [1]
Databricks ofrece la posibilidad de poder desplegar el plano de datos sobre una VNET propia administrada por el cliente. Esta solución ofrece mayor versatilidad y control sobre los diferentes componentes de nuestra arquitectura.
- La comunicación entre el Data Plane y Control Plane se realizará sobre el backbone interno de Azure de la misma forma que en la red administrada por Databricks vista anteriormente, además de la misma forma podremos activar SCC.
- En este caso al ser nuestra propia VNET tendremos control sobre las reglas definidas en nuestros NSG.
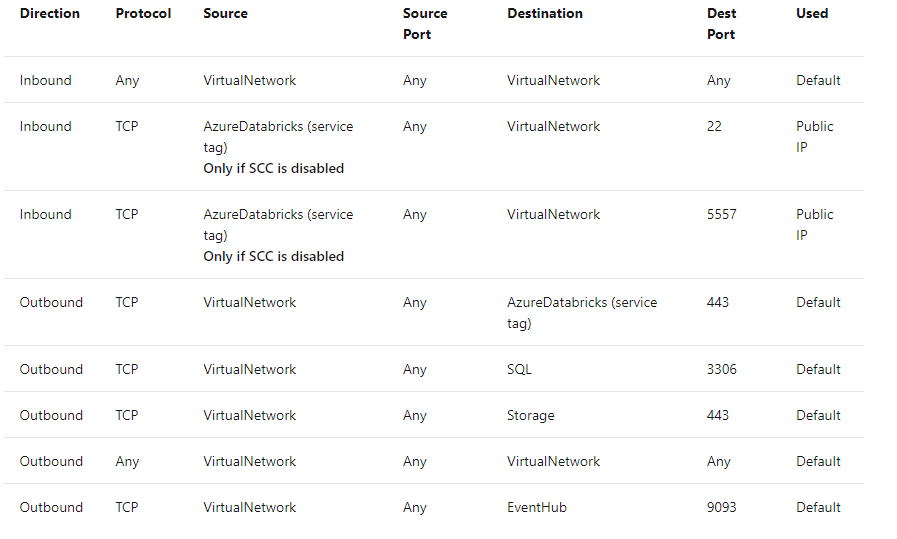
- Se deberá ser propietario de la VNET para poder permitir que se delegue a Databricks su configuración o el despliegue de recursos [3].
- Podremos habilitar cualquier componente de arquitectura que consideremos dentro de nuestra VNET ya que estará administrada por nosotros:
- Conectar Azure Databricks a otros servicios de Azure de una forma más segura empleando service endpoints o private endpoints.
- Conectarse a tus recursos on-premise empleando user-defined routes.
- Permite desplegar un network virtual appliance para inspeccionar el tráfico
- Custom DNS
- Custom egress NSG rules
- Aumentar el rango CIDR de la máscara de red para la VNET entre /16 – /24 y /26 para las subredes.
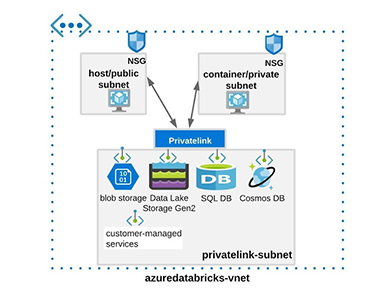
Dentro de las peculiaridades de ambos despliegues, es importante señalar:
- No es posible reemplazar una VNet existente en un workspace por otra, si fuera necesario se deberá crear un nuevo workspace con una nueva VNET.
- Tampoco es posible añadir SCC a un workspace una vez ya ha sido creado, si fuera necesario también deberá volver a crear el workspace.
Conexiones contra el plano de control
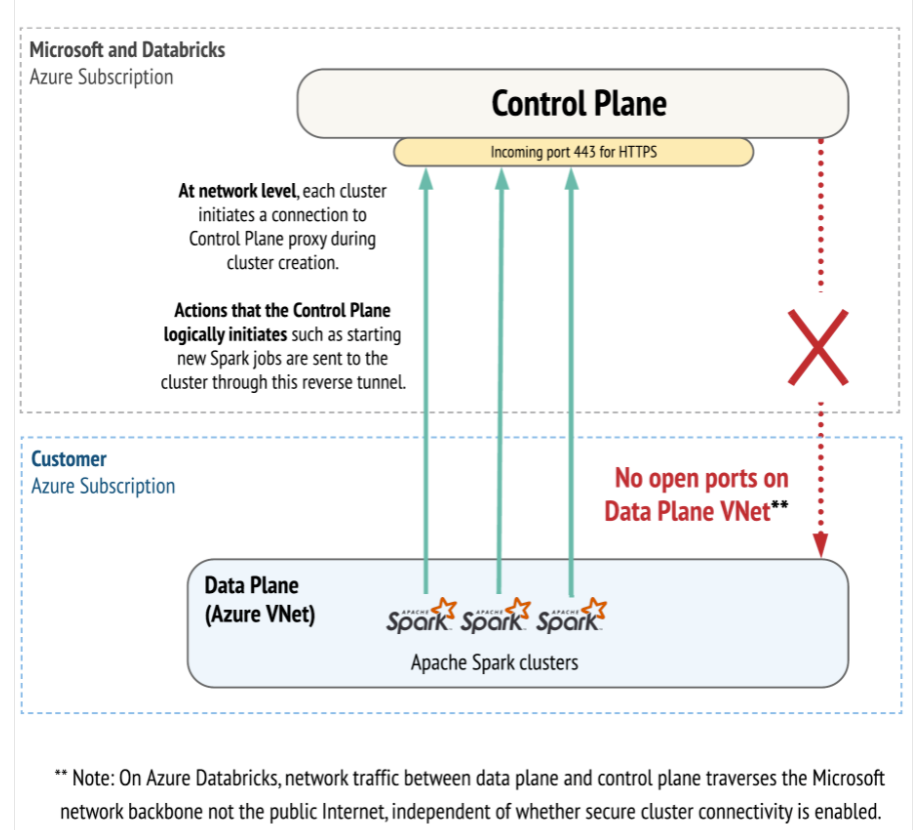
Tal y como ya hemos comentado anteriormente, toda comunicación con el plano de control se realiza por dentro del backbone de Azure por defecto [2]. También se debe destacar:
- A nivel de red, toda conexión que se realiza contra el plano de control al crear un cluster en el plano de datos se realiza vía HTTPS (443) y sobre una dirección IP diferente a la empleada para otros servicios de aplicación Web o APIs.
- Cuando el plano de control lanza nuevos jobs o realiza otras tareas de administración del clúster, estas solicitudes se envían al clúster a través de este túnel inverso.
- Para realizar las conexiones entre el plano de control y de datos, se habilitará una dirección IP pública sobre la subred pública aunque el tráfico posteriormente sea enrutado dentro del backbone, además no se dejarán puertos abiertos o se asignarán direcciones IP públicas sobre los clusters.
- Si en nuestro caso de uso se deben de emplear unas condiciones más restrictivas de seguridad, Databricks ofrece la posibilidad de activar la opción de secure cluster connectivity permitiendo eliminar toda dirección IP pública para realizar la conexión entre el plano de control y de datos, para ello se servirá:
- Por defecto en la red administrada por Databricks (managed VNET) se habilita un NAT para poder realizar esta comunicación.
- Si el cliente despliega la infraestructura sobre su propia red (VNET Injection deployment) este deberá aportar un dispositivo de red para el tráfico saliente, que podra ser un NAT Gateway, Load Balancer, Azure Firewall o un dispositivo de terceros.
Identidad y Gestión de accesos
Databricks ofrece diferentes herramientas para administrar el acceso a nuestros recursos y servicios de Azure de una forma sencilla e integrada en la propia plataforma.
Podremos encontrar herramientas como filtrados de IP, SSO, permisos de uso sobre los servicios de Databricks, acceso a secretos, etc.
IP access lists
Databricks permite a los administradores definir listas de acceso IP para restringir el acceso a la interfaz de usuario y la API a un determinado conjunto de direcciones IP y subredes, permitiendo el acceso solo desde las redes de la organización. Los administradores sólo podrán realizar la gestión de IP access list con el API REST.
Single sign on (SSO)
Mediante Azure Active Directory podremos configurar SSO para todos nuestros usuarios de Databricks evitando la duplicación en la gestión de identidades.
System for Cross-domain Identity Management (SCIM)
Permite a través de un IdP (actualmente Azure Active Directory) crear usuarios en Azure Databricks y otorgarles un nivel de permisos y permanecer sincronizados, se debe disponer de un plan PREMIUM. Si los permisos son revocados los recursos ligados a este usuario no son eliminados.
Acceso a recursos
El acceso principal a los diferentes servicios de Databricks vendrá dado por los entitlements donde se indicará si el grupo/usuario tendrá acceso a cada uno de ellos (cluster creation, Databricks SQL, Workspaces)
Por otro lado, dentro de Databricks se pueden emplear ACLs para configurar el acceso a los diferentes recursos como clusters,tablas, pools, jobs y objetos del workspace (notebooks, directorios, modelos, etc). Otorgar esta granularidad sobre el acceso a los recursos solo está disponible mediante el plan PREMIUM, por defecto todos los usuarios tendrán acceso a los recursos.
Estos permisos se encuentran gestionados desde el usuario administrador u otros usuarios con permisos delegados.
Existen 5 niveles de permisos con sus múltiples implicaciones dependiendo del recurso al que se apliquen; No permissions, can read, can run, can edit, can manage.
A continuación, se indican los permisos asociados al recurso que se desea emplear. En caso de que dos políticas puedan solaparse, la opción más restrictiva primará sobre la otra.
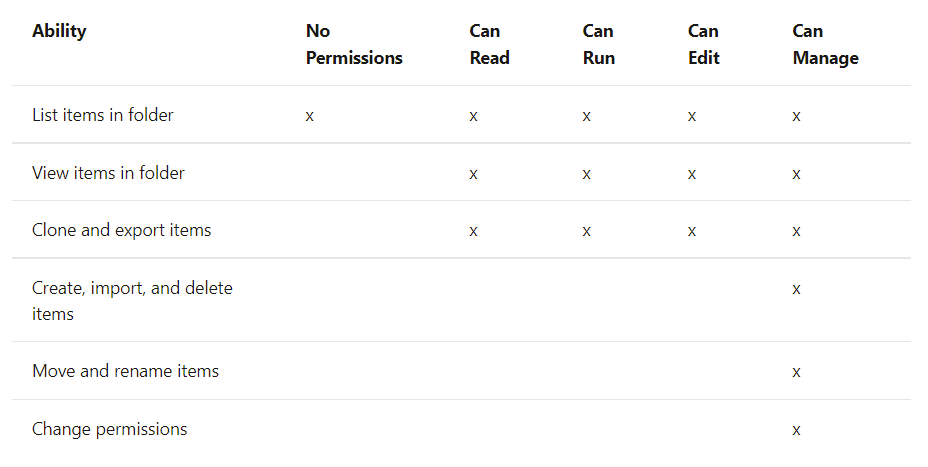
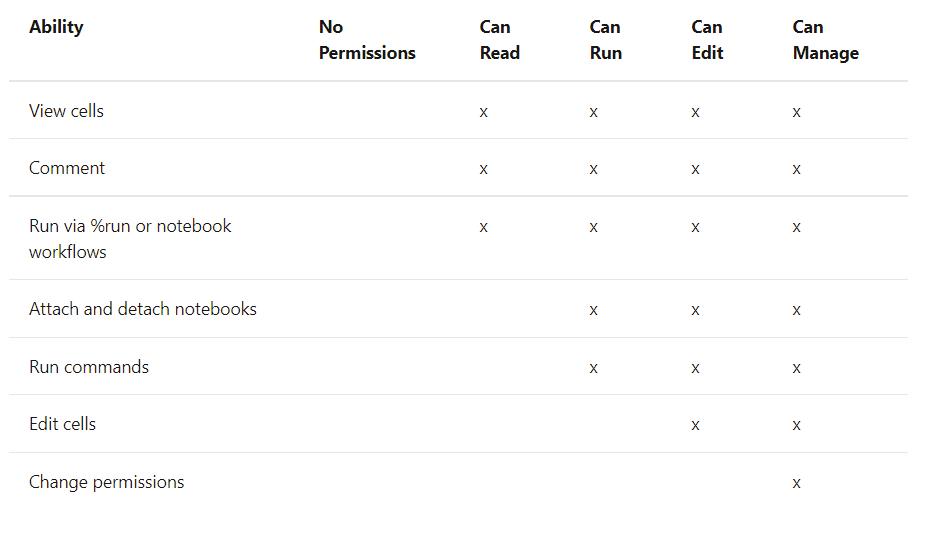
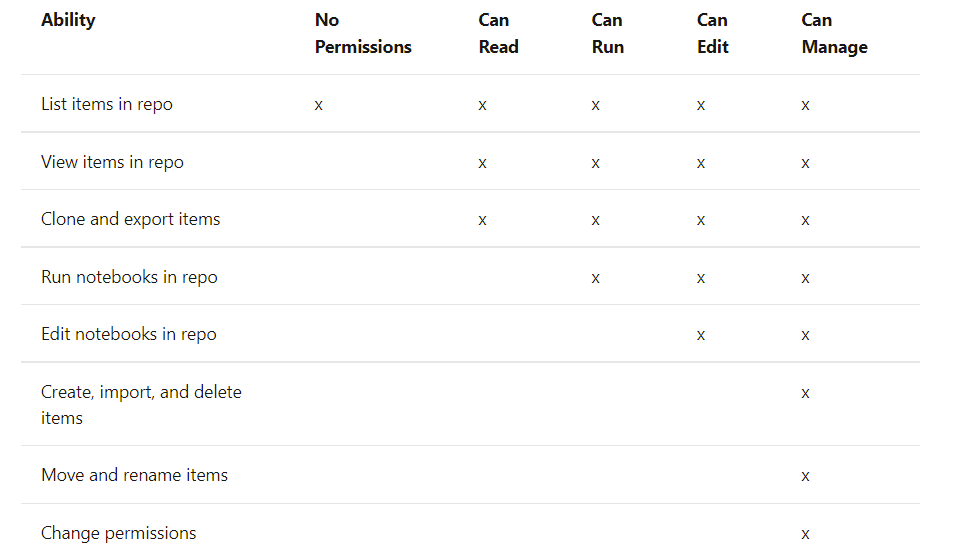

Secretos [5]
Accesos
Por defecto, todos los usuarios sin importar el plan contratado pueden crear secretos y acceder a ellos (MANAGE permission). Solo a través del plan PREMIUM es posible configurar permisos granulares para controlar el acceso. La gestión de estos se podrá realizar a través de Secrets API 2.0 o Databricks CLI (0.7.1 en adelante).
La gestión de los secretos se realiza a nivel de scope (colección de secretos identificados por un nombre), en concreto una ACL controla la relación entre el principal (usuario o grupo), el scope y el nivel de permiso. Por ejemplo: cuando un usuario accede al secreto desde un notebook vía Secrets utility el nivel de permiso se aplica en base a quien ejecuta el comando.
Por defecto, cuando un scope es creado se le aplica un nivel de permiso MANAGE, sin embargo el usuario que crea el scope podrá añadir permisos granulares.
Distinguimos 3 niveles de permiso en Databricks-backed scopes:
- Manage: Puede modificar las ACLs y además tiene permisos de lectura y escritura sobre el scope.
- WRITE: tiene permisos de lectura y escritura sobre el scope.
- READ: solo tiene permisos de lectura sobre el scope y los secretos a los que tiene acceso.
Los usuarios administradores de un workspace tienen acceso a todos los secretos de todos los scopes
Almacenamiento
Los secretos podrán ser referenciados desde los scopes que a su vez harán referencia a sus respectivos vaults donde los secretos son almacenados.
Existen dos tipos de soporte de almacenamiento para los secretos:
- Databricks-backed
- Azure Key Vault
Podremos emplear Databricks-backed como soporte de almacenamiento de los secretos sin la necesidad de un plan PREMIUM, sin embargo ya sea tanto para emplear Azure Key Vault o por otro lado el empleo de permisos granulares en ambos soportes, sí será necesario contratar el plan PREMIUM.
Es importante destacar que si el Key Vault existe en un tenant diferente al que alberga el workspace de Databricks, el usuario que crea el scope debe de tener permisos para crear service principals sobre el key vault del tenant, de lo contrario se arrojará el siguiente error.
Unable to grant read/list permission to Databricks service principal to KeyVault Debido a que Azure Key Vault es ajeno a Databricks solo será posible realizar operaciones de lectura por defecto y no pueden ser administradas desde Secrets API 2.0, deberá emplearse por contra Azure SetSecrets REST API o desde el portal de Azure UI.
Es importante señalar, que todos los usuarios tendrán acceso a los secretos de un mismo Key Vault aunque se encuentren en diferentes scopes. Se considera buena práctica replicar los secretos en diferentes Key Vaults según subgrupos se tengan aunque puedan ser redundantes.
Ahora mediante RBAC [4] (role-based access control) ya es posible mediante diferentes roles controlar el acceso a los secretos del Vault desde Azure.
Por último, simplemente indicar que los scopes podrán consumirse desde la librería dbutils, si el valor es cargado correctamente aparece referenciado como REDACTED.
dbutils.secrets.get(scope = "nombre_scope_databricks", key = "nombre_secreto") Conexiones on-premise
Por último, indicar que es posible establecer una conexión on-premise para nuestro plano de datos en Azure, para ello es indispensable que este se encuentre alojado en nuestra propia red mediante VNET injection.
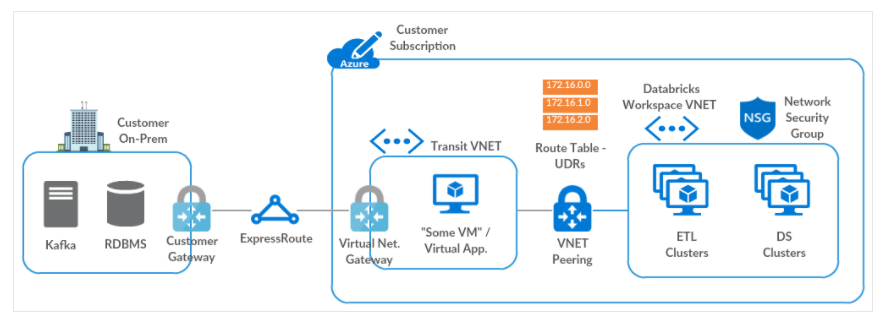
Azure define como principal método el uso de Transit Virtual Network para establecer esta conexión on-premise, siguiendo los siguientes pasos:
- Crear un Network Gateway (VPN o ExpressRoute) entre la red de tránsito y on-premise, para ello deberemos crear tanto el Customer Gateway en el lado on-premise como el Virtual Gateway en el lado de Azure.
- Deberemos establecer el peering entre el plano de datos y la red de tránsito. Una vez establecido, Azure Transit configura todas las rutas, sin embargo no se incluyen las de retorno hasta el plano de control para los clusters de Databricks, para ello se deberán configurar las user-defined routes y asociarlas a las subredes del plano de datos.
Otras soluciones alternativas también podrían emplearse mediante el uso de Custom DNS o el empleo de un virtual appliance o firewalls.
Referencias
[1] Customer Managed VNET Databricks Guide. [link] (Enero 26, 2022)
[2] Secure Cluster Connectivity. [link] (Enero 26, 2022)
[3] Subnet Delegation. [link] (Enero 3, 2022)
[4] Role-based access control [link] (Octubre 27, 2021)
[5] Databricks secrets scopes [link] (Enero 26, 2022)
Navegación
Planes y tipos de carga de trabajo
Identidad y Gestión de accesos
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
DESCUBRE BLUETAB
Compartir en twitter
Compartir en linkedin
Gabriel Gallardo Ruiz
Senior Data Architect
SOLUCIONES, SOMOS EXPERTOS