Databricks sobre AWS – Una perspectiva de arquitectura (parte 1)

Jon Garaialde
Cloud Data Solutions Engineer/Architect

Rubén Villa
Big Data & Cloud Architect

Alfonso Jerez
Analytics Engineer | GCP | AWS | Python Dev | Azure | Databricks | Spark

Alberto Jaén
Cloud Engineer | 3x AWS Certified | 2x HashiCorp Certified | GitHub: ajaen4

Databricks se ha convertido en un producto de referencia en el ámbito de plataformas de análisis unificadas para crear, implementar, compartir y mantener soluciones de datos, proporcionando un entorno para los roles de ingeniería y analítica. Debido a que no todas las organizaciones tienen los mismos tipos de carga de trabajo, Databricks ha diseñado diferentes planes que permiten adaptarse a las distintas necesidades, y esto tiene un impacto directo en el diseño de la arquitectura de la plataforma.
Con esta serie de artículos, se pretende abordar la integración de Databricks en entornos AWS, analizando las alternativas ofrecidas por el producto respecto al diseño de arquitectura, además se abordarán las bondades de la plataforma de Databricks por sí misma. Debido a la extensión de los contenidos, se ha considerado conveniente dividirlos en tres entregas:
Primera entrega:
- Introducción.
- Data Lakehouse & Delta.
- Conceptos.
- Arquitectura.
- Planes y tipos de carga de trabajo.
- Networking.
Segunda entrega:
- Seguridad.
- Persistencia.
- Billing.
Introducción
Databricks se crea con la idea de poder desarrollar un entorno único en el que distintos perfiles (como Data Engineers, Data Scientists y Data Analysts) puedan trabajar de forma colaborativa sin la necesidad de contar con proveedores de servicios externos que ofrezcan las distintas funcionalidades que cada uno de estos necesita en su día a día.
El área de trabajo de Databricks proporciona una interfaz unificada y herramientas para la mayoría de las tareas de datos, entre las que se incluyen:
- Programación y administración de procesamiento de datos.
- Generación de paneles y visualizaciones.
- Administración de la seguridad, la gobernanza, la alta disponibilidad y la recuperación ante desastres.
- Detección, anotación y exploración de datos.
- Modelado, seguimiento y servicio de modelos de Machine Learning (ML).
- Soluciones de IA generativa.
El nacimiento de Databricks se lleva a cabo gracias a la colaboración de los fundadores de Spark, publicando Delta Lake y MLFlow como productos de Databricks siguiendo la filosofía open-source.

Este nuevo entorno colaborativo tuvo un gran impacto en su presentación debido a las novedades que ofrecía al integrarse las distintas tecnologías:
- Spark es un framework de programación distribuida que presenta como una de sus funcionalidades la capacidad de realizar consultas sobre los Delta Lakes en unos ratios de coste/tiempo superiores a los de la competencia, consiguiendo optimizar los procesos de análisis.
- Delta Lake se presenta como soporte de almacenamiento de Spark. Aúna las principales ventajas de los Data WareHouse y Data Lakes al posibilitar la carga de información estructurada y no estructurada mediante una versión mejorada de Parquet que permite soportar transacciones ACID asegurando así la integridad de la información en los procesos ETL llevados a cabo por Spark.
- MLFlow es una plataforma para la administración del ciclo de vida de Machine Learning que incluye: experimentación, reusabilidad, implementación y registro de modelos centralizados.
Data Lakehouse & Delta
Un Data Lakehouse es un sistema de gestión de datos que combina los beneficios de los Data Lakes y los Data Warehouses.
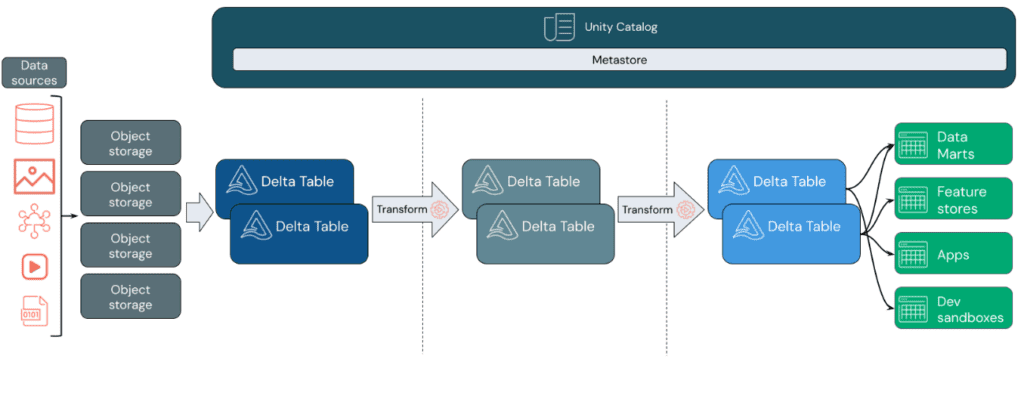
Un Data Lakehouse proporciona capacidades de almacenamiento y procesamiento escalables para organizaciones modernas que desean evitar sistemas aislados para procesar diferentes cargas de trabajo, como el aprendizaje automático (ML) y la inteligencia empresarial (BI). Un Data Lakehouse puede ayudar a establecer una única fuente de verdad, eliminar costes redundantes y garantizar la actualización de los datos.
Los Data Lakehouses utilizan un patrón de diseño de datos que mejora, enriquece y refina gradualmente los datos a medida que avanzan a través de diferentes capas. Este patrón se conoce frecuentemente como arquitectura de medallón.
Databricks se basa en Apache Spark. Apache Spark habilita un motor enormemente escalable que se ejecuta en recursos informáticos desacoplados del almacenamiento.
El Data Lakehouse de Databricks utiliza dos tecnologías clave adicionales:
- Delta Lake: capa de almacenamiento optimizada que admite transacciones ACID y aplicación de esquemas.
- Unity Catalog: solución de gobernanza unificada y detallada para datos e inteligencia artificial.
Patrón de diseño de datos
- Ingesta de datos
En la capa de ingesta, los datos llegan desde diversas fuentes en lotes o en streaming, en una amplia gama de formatos. Esta primera etapa proporciona un punto de entrada para los datos en su forma sin procesar. Al convertir estos archivos en tablas Delta, se pueden aprovechar las capacidades de aplicación de esquemas de Delta Lake para identificar y manejar datos faltantes o inesperados.
Para gestionar y registrar estas tablas de manera eficiente según los requisitos de gobierno de datos y los niveles de seguridad necesarios, se puede utilizar Unity Catalog. Este catálogo permite realizar un seguimiento del linaje de los datos a medida que se transforman y refinan, al mismo tiempo que facilita la aplicación de un modelo unificado de gobernanza para mantener la privacidad y la seguridad de los datos confidenciales.
- Procesamiento, curación e integración de datos
Después de verificar los datos, se procede a la selección y refinamiento. En esta etapa, los científicos de datos y los profesionales de aprendizaje automático suelen trabajar con los datos para combinarlos, crear nuevas características y completar la limpieza. Una vez que los datos estén completamente limpios, se pueden integrar y reorganizar en tablas diseñadas para satisfacer las necesidades comerciales específicas.
El enfoque de esquema en la escritura, junto con las capacidades de evolución del esquema de Delta, permite realizar cambios en esta capa sin necesidad de reescribir la lógica subyacente que proporciona datos a los usuarios finales.
- Servicio de datos
La última capa proporciona datos limpios y enriquecidos a los usuarios finales. Las tablas finales deben estar diseñadas para satisfacer todas las necesidades de uso. Gracias a un modelo de gobernanza unificado, se puede rastrear el linaje de los datos hasta su fuente de verdad única. Los diseños de datos optimizados para diversas tareas permiten a los usuarios acceder a los datos para aplicaciones de aprendizaje automático, ingeniería de datos, inteligencia empresarial e informes.
Características
- El concepto de Data Lakehouse se basa en aprovechar un Data Lake para almacenar una amplia variedad de datos en sistemas de almacenamiento de bajo coste, como Amazon S3 en este caso. Esto se complementa con la implementación de sistemas que aseguren la calidad y fiabilidad de los datos almacenados, garantizando la coherencia incluso cuando se accede a ellos desde múltiples fuentes simultáneamente.
- Se emplean catálogos y esquemas para proporcionar mecanismos de gobernanza y auditoría, permitiendo operaciones de manipulación de datos (DML) mediante diversos lenguajes, y almacenando historiales de cambios y snapshots de datos. Además, se aplican controles de acceso basados en roles para garantizar la seguridad.
- Se emplean técnicas de optimización de rendimiento y escalabilidad para garantizar un funcionamiento eficiente del sistema.
- Permite el uso de datos no estructurados y no-SQL, además de facilitar el intercambio de información entre plataformas utilizando formatos de código abierto como Parquet y ORC, y ofreciendo APIs para un acceso eficiente a los datos.
- Proporciona soporte para streaming de extremo a extremo, eliminando la necesidad de sistemas dedicados para aplicaciones en tiempo real. Esto se complementa con capacidades de procesamiento masivo en paralelo para manejar diversas cargas de trabajo y análisis de manera eficiente.
Conceptos: Account & Workspaces
En Databricks, un workspace es una implementación de Databricks en la nube que funciona como un entorno para que su equipo acceda a los activos de Databricks. Se puede optar por tener varios espacios de trabajo o solo uno, según las necesidades.
Una cuenta de Databricks representa una única entidad que puede incluir varias áreas de trabajo. Las cuentas habilitadas para Unity Catalog se pueden usar para administrar usuarios y su acceso a los datos de forma centralizada en todos los workspaces de la cuenta. La facturación y el soporte también se manejan a nivel de cuenta.
Billing: Databricks units (DBUs)
Las facturas de Databricks se basan en unidades de Databricks (DBU), unidades de capacidad de procesamiento por hora según el tipo de instancia de VM.
Authentication & Authorization
Conceptos relacionados con la administración de identidades de Databricks y su acceso a los activos de Databricks.
- User: un individuo único que tiene acceso al sistema. Las identidades de los usuarios están representadas por direcciones de correo electrónico.
- Service Principal: identidad de servicio para usar con jobs, herramientas automatizadas y sistemas como scripts, aplicaciones y plataformas CI/CD. Las entidades de servicio están representadas por un ID de aplicación.
- Group: colección de identidades. Los grupos simplifican la gestión de identidades, facilitando la asignación de acceso a workspaces, datos y otros objetos. Todas las identidades de Databricks se pueden asignar como miembros de grupos.
- Access control list (ACL): lista de permisos asociados al workspace, cluster, job, tabla o experimento. Una ACL especifica a qué usuarios o procesos del sistema se les concede acceso a los objetos, así como qué operaciones están permitidas en los activos. Cada entrada en una ACL típica especifica un tema y una operación.
- Personal access token: cadena opaca para autenticarse en la API REST, almacenes SQL, etc.
- UI: interfaz de usuario de Databricks, es una interfaz gráfica para interactuar con características, como carpetas del workspace y sus objetos contenidos, objetos de datos y recursos computacionales.
Data science & Engineering
Las herramientas de ingeniería y ciencia de datos ayudan a la colaboración entre científicos de datos, ingenieros de datos y analistas de datos.
- Workspace: entorno para acceder a todos los activos de Databricks, organiza objetos (Notebooks, bibliotecas, paneles y experimentos) en carpetas y proporciona acceso a objetos de datos y recursos computacionales.
- Notebook: interfaz basada en web para crear flujos de trabajo de ciencia de datos y aprendizaje automático que pueden contener comandos ejecutables, visualizaciones y texto narrativo.
- Dashboard: interfaz que proporciona acceso organizado a visualizaciones.
- Library: paquete de código disponible que se ejecuta en el cluster. Databricks incluye muchas bibliotecas y se pueden agregar las propias.
- Repo: carpeta cuyos contenidos se versionan juntos sincronizándolos con un repositorio Git remoto. Databricks Repos se integra con Git para proporcionar control de código fuente y de versiones para los proyectos.
- Experiment: colección de ejecuciones de MLflow para entrenar un modelo de aprendizaje automático.
Databricks interfaces
Describe las interfaces que admite Databricks, además de la interfaz de usuario, para acceder a sus activos: API y línea de comandos (CLI).
- REST API: Databricks proporciona documentación API para el workspace y la cuenta.
- CLI: proyecto de código abierto alojado en GitHub. La CLI se basa en la API REST de Databricks.
Data management
Describe los objetos que contienen los datos sobre los que se realiza el análisis y alimenta los algoritmos de aprendizaje automático.
- Databricks File System (DBFS): capa de abstracción del sistema de archivos sobre un almacén de blobs. Contiene directorios, que pueden contener archivos (archivos de datos, bibliotecas e imágenes) y otros directorios.
- Database: colección de objetos de datos, como tablas o vistas y funciones, que está organizada para que se pueda acceder a ella, administrarla y actualizarla fácilmente.
- Table: representación de datos estructurados.
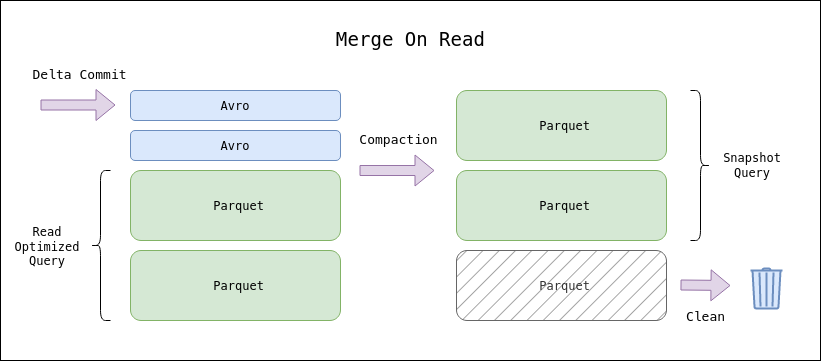
- Delta table: de forma predeterminada, todas las tablas creadas en Databricks son tablas delta. Las tablas delta se basan en el proyecto de código abierto Delta Lake, un marco para el almacenamiento de tablas ACID de alto rendimiento en almacenes de objetos en la nube. Una tabla Delta almacena datos como un directorio de archivos en el almacenamiento de objetos en la nube y registra los metadatos de la tabla en el metastore dentro de un catálogo y un esquema.
- Metastore: componente que almacena toda la información de la estructura de las distintas tablas y particiones en el almacén de datos, incluida la información de columnas y tipos de columnas, los serializadores y deserializadores necesarios para leer y escribir datos, y los archivos correspondientes donde se almacenan los datos. Cada implementación de Databricks tiene un metastore central de Hive al que pueden acceder todos los clusters para conservar los metadatos de la tabla.
- Visualization: representación gráfica del resultado de ejecutar una consulta.
Computation management
Describe los conceptos para la ejecución de cálculos en Databricks.
- Cluster: conjunto de configuraciones y recursos informáticos en los que se ejecutan Notebooks y jobs. Hay dos tipos de clusters: all-purpose y job.
- Un cluster all-purpose se crea mediante la interfaz de usuario, la CLI o la API REST, pudiendo finalizar y reiniciar manualmente este tipo de clusters.
- Un cluster job se crea cuando se ejecuta un job en un nuevo cluster job y finaliza cuando se completa el job. Los jobs cluster no pueden reiniciar.
- Pool: conjunto de instancias y listas para usar que reducen los tiempos de inicio y escalado automático del cluster. Cuando se adjunta a un pool, un cluster asigna los nodos driver y workers al pool. Si el pool no tiene suficientes recursos para atender la solicitud del cluster, el pool se expande asignando nuevas instancias del proveedor de instancias. Cuando se finaliza un cluster adjunto, las instancias que utilizó se devuelven al pool y pueden ser reutilizadas por un cluster diferente.
- Databricks runtime: conjunto de componentes principales que se ejecutan en los clusters administrados por Databricks. Se disponen de los siguientes runtimes:
- Databricks runtime incluye Apache Spark, además agrega una serie de componentes y actualizaciones que mejoran sustancialmente la usabilidad, el rendimiento y la seguridad del análisis.
- Databricks runtime para Machine Learning se basa en Databricks runtime y proporciona una infraestructura de aprendizaje automático prediseñada que se integra con todas las capacidades del workspace de Databricks. Contiene varias bibliotecas populares, incluidas TensorFlow, Keras, PyTorch y XGBoost.
- Workflows: marcos para desarrollar y ejecutar canales de procesamiento de datos:
- Jobs: mecanismo no interactivo para ejecutar un Notebook o una biblioteca, ya sea de forma inmediata o programada.
- Delta Live Tables: marco para crear canales de procesamiento de datos confiables, mantenibles y comprobables.
- Workload: Databricks identifica dos tipos de cargas de trabajo sujetas a diferentes esquemas de precios:
- Ingeniería de datos (job): carga de trabajo (automatizada) que se ejecuta en un cluster job que Databricks crea para cada carga de trabajo.
- Análisis de datos (all-purpose): carga de trabajo (interactiva) que se ejecuta en un cluster all-purpose. Las cargas de trabajo interactivas normalmente ejecutan comandos dentro de un Notebooks de Databricks. En cualquier caso, ejecutar un job en un cluster all-purpose existente también se trata como una carga de trabajo interactiva.
- Execution context: estado de un entorno de lectura, evaluación e impresión (REPL) para cada lenguaje de programación admitido. Los lenguajes admitidos son Python, R, Scala y SQL.
Machine learning
Entorno integrado de extremo a extremo que incorpora servicios administrados para el seguimiento de experimentos, entrenamiento de modelos, desarrollo y administración de funciones, y servicio de funciones y modelos.
- Experiments: principal unidad de organización para el seguimiento del desarrollo de modelos de aprendizaje automático. Los experimentos organizan, muestran y controlan el acceso a ejecuciones registradas individuales de código de entrenamiento de modelos.
- Feature Store: repositorio centralizado de funciones. Permite compartir y descubrir funciones en toda su organización y también garantiza que se utilice el mismo código de cálculo de funciones para el entrenamiento y la inferencia del modelo.
- Models & model registry: modelo de aprendizaje automático o aprendizaje profundo que se ha registrado en el registro de modelos.
SQL
- SQL REST API: interfaz que permite automatizar tareas en objetos SQL.
- Dashboard: representación de visualizaciones de datos y comentarios.
- SQL queries: consultas SQL en Databricks.
- Consulta.
- Almacén SQL.
- Historial de consultas.
Arquitectura: Arquitectura a alto nivel
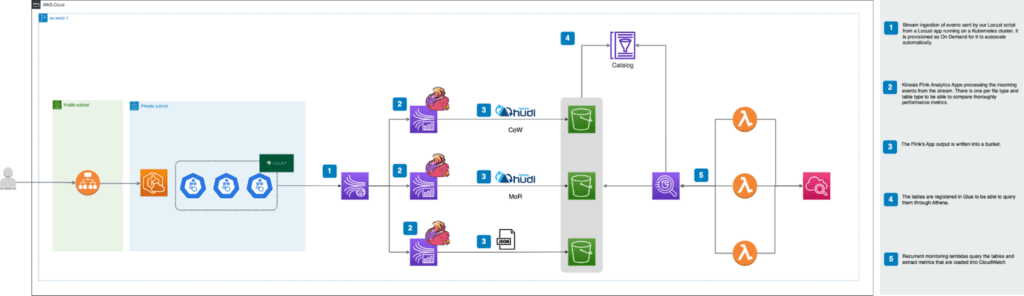
Antes de comenzar a analizar las diferentes alternativas que nos proporciona Databricks respecto al despliegue de infraestructura, conviene conocer los principales componentes del producto. A continuación, una descripción general a alto nivel de la arquitectura de Databricks, incluida su arquitectura empresarial, en combinación con AWS.

Aunque las arquitecturas pueden variar según las configuraciones personalizadas, el diagrama anterior representa la estructura y el flujo de datos más común para Databricks en entornos de AWS.
El diagrama describe la arquitectura general del compute plane clásico. Al respecto de la arquitectura sobre el compute plane serverless que se utiliza para los almacenes SQL sin servidor, la capa de computación se aloja en una cuenta de Databricks en vez de en una cuenta de AWS.
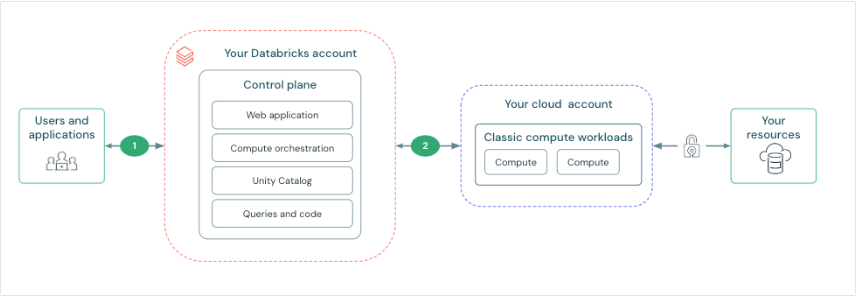
Control plane y compute plane
Databricks está estructurado para permitir una colaboración segura en equipos multifuncionales y, al mismo tiempo, mantiene una cantidad significativa de servicios de backend administrados por Databricks para que pueda concentrarse en sus tareas de ciencia de datos, análisis de datos e ingeniería de datos.
Databricks opera desde un control plane y compute plane.
- El control plane incluye los servicios backend que Databricks administra en su cuenta de Databricks. Los Notebooks y muchas otras configuraciones del workspace se almacenan en el control plane y se cifran en reposo.
- El compute plane es donde se procesan los datos.
- Para la mayoría de los cálculos de Databricks, los recursos informáticos se encuentran en su cuenta de AWS, en lo que se denomina el compute plane clásico. Esto se refiere a la red en su cuenta de AWS y sus recursos. Databricks usa el compute plane clásico para sus Notebooks, jobs y almacenes SQL de Databricks clásicos y profesionales.
- Tal y como adelantábamos, para los almacenes SQL serverless, los recursos informáticos serverless se ejecutan en un compute plane sin servidor en una cuenta de Databricks.
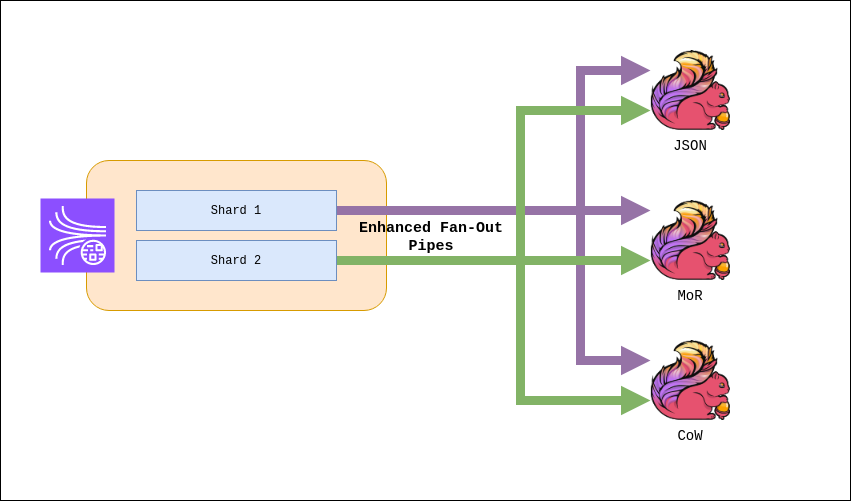
Existen multitud de conectores de Databricks para conectar clusters a orígenes de datos externos fuera de la cuenta de AWS, para ingerir datos o almacenarlos. También con el objeto de ingerir datos de fuentes de transmisión externas, como datos de eventos, de transmisión, de IoT, etc.
El Data Lake se almacena en reposo en la cuenta de AWS y en las propias fuentes de datos para mantener el control y la propiedad de los datos.
Arquitectura E2
La plataforma E2 proporciona características tales como:
- Multi-workspace accounts.
- Customer-managed VPCs: creación de workspaces de Databricks en la propia VPC en lugar de utilizar la arquitectura predeterminada en la que los clusters se crean en una única VPC de AWS que Databricks crea y configura en su cuenta de AWS.
- Secure cluster connectivity: también conocida como «Sin IP públicas», la conectividad de clusters segura permite lanzar clusters en los que todos los nodos tienen direcciones IP privadas, lo que proporciona una seguridad mejorada.
- Customer-managed keys: proporcione claves KMS para el cifrado de datos.
Planes y tipos de carga de trabajo
El precio indicado por Databricks se imputa en relación con las DBUs consumidas por los clusters. Este parámetro está relacionado con la capacidad de procesamiento consumida por los clusters y dependen directamente del tipo de instancias seleccionadas (al configurar el cluster se facilita un cálculo aproximado de las DBUs que consumirá por hora el cluster).
El precio imputado por DBU depende de dos factores principales:
- Factor computacional: la definición de las características del cluster (Cluster Mode, Runtime, On-Demand-Spot Instances, Autoscaling, etc.) que se traducirá en la asignación de un paquete en concreto.
- Factor de arquitectura: la personalización de esta (Customer Managed-VPC), en algunos aspectos requerirá tener una suscripción Premium e incluso Enterprise, lo que genera que el coste de cada DBU sea mayor a medida que se obtiene una suscripción con mayores privilegios.
La combinación de ambos factores, computacional y de arquitectura, definirá el coste final de cada DBU por hora de trabajo.
Toda la información relativa a planes y tipos de trabajo se puede encontrar en el siguiente enlace
Networking
Databricks tiene una arquitectura dividida en control plane y compute plane. El control plane incluye servicios backend gestionados por Databricks, mientras que el compute plane procesa los datos. Para el cómputo y cálculo clásico, los recursos están en la cuenta de AWS en un classic compute plane. Para el cómputo serverless, los recursos corren en un serverless compute plane en la cuenta de Databricks.
De esta forma, Databricks proporciona conectividad de red segura de manera predeterminada, pero se pueden configurar funciones adicionales. A destacar:
- La conexión entre usuarios y Databricks: esta puede ser controlada y configurada para una conectividad privada. Dentro de las características que se pueden configurar tenemos:
- Autenticación y control de acceso.
- Conexión privada.
- Lista de IPs de acceso.
- Reglas de Firewall.
- Características de conectividad de red para control plane y compute plane. La conectividad entre el control plane y el serverless compute plane siempre se realiza a través de la red en la nube, no a través de Internet público. Este enfoque se centra en establecer y asegurar la conexión entre el control plane y el classic compute plane. Destacar el concepto de «conectividad segura de cluster», que, cuando está habilitado, implica que las redes virtuales del cliente no tienen puertos abiertos y los nodos del cluster de Databricks no tienen direcciones IP públicas, simplificando así la administración de la red. Por otro lado, existe la opción de implementar un espacio de trabajo en la propia Virtual Private Cloud (VPC) en AWS, lo que permite un mayor control sobre la cuenta de AWS y limita las conexiones salientes. Otros temas incluyen la posibilidad de emparejar la VPC de Databricks con otra VPC de AWS para mayor seguridad, y habilitar la conectividad privada desde el control plane al classic compute plane mediante AWS PrivateLink.
Se proporciona el siguiente enlace para obtener más información sobre estas características específicas
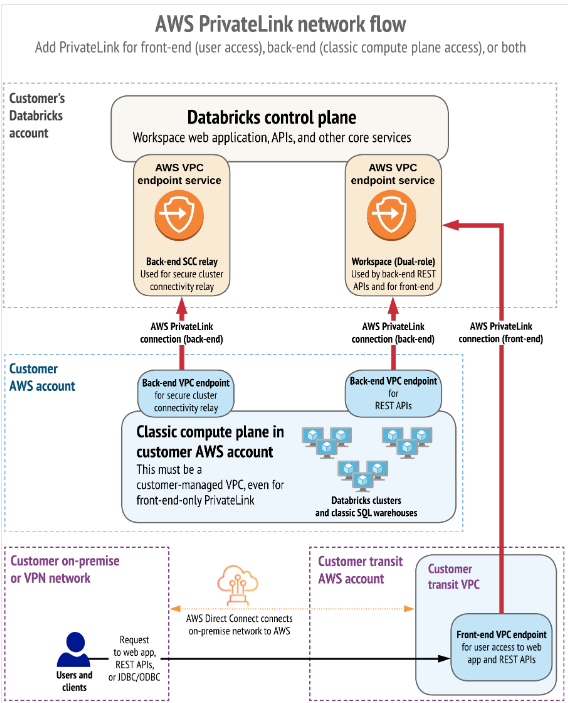
Conexiones a través de red privada (Private Links)
Por último, queremos destacar como AWS utiliza los PrivateLink para establecer una conectividad privada entre usuarios y los workspaces de Databricks, así como entre los clusters y la infraestructura de los workspaces.
AWS PrivateLink proporciona conectividad privada desde las VPC de AWS y las redes locales hacia los servicios de AWS sin exponer el tráfico a la red pública. En Databricks, las conexiones PrivateLink se admiten para dos tipos de conexiones: Front-end (users a workspaces) y back-end (control plane al control plane).
La conexión front-end permite a los usuarios conectarse a la aplicación web, la API REST y la API Databricks Connect a través de un punto de conexión de interfaz VPC.
La conexión back-end implica que los clusters de Databricks Runtime en una VPC administrada por el cliente se conectan a los servicios centrales del workspace en la cuenta de Databricks para acceder a las API REST.
Se pueden implementar ambas conexiones PrivateLink o únicamente una de ellas.
Referencias
Navegación
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
Jon Garaialde
Cloud Data Solutions Engineer/Architect
Alfonso Jerez
Analytics Engineer | GCP | AWS | Python Dev | Azure | Databricks | Spark
Rubén Villa
Big Data & Cloud Architect
Alberto Jaén
Cloud Engineer | 3x AWS Certified | 2x HashiCorp Certified | GitHub: ajaen4
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar