Gobierno del Dato: Una mirada en la realidad y el futuro

Silvia Juliana Rueda Urrea
Experienced Consultant

En las últimas décadas las organizaciones han cambiado continuamente desde una mirada en el mejoramiento, el aprovechamiento de las oportunidades, la innovación y los ejes diferenciadores para superar a la competencia.
Un claro ejemplo de lo expuesto, es el gobierno del dato, para organizar la información, mantener una mejor comunicación con los consumidores y tomar decisiones.
Para White (2019), es indispensable que las organizaciones adopten el gobierno del dato para mejorar su rendimiento organizacional, brindar oportunidades a los clientes y contribuir al desarrollo de cualquier actor dentro de las empresas; además de logar a mediano plazo estar en el mundo globalizado de la virtualidad.
Desde este punto de vista, el gobierno de datos ayuda a tener una ventaja competitiva, superar los obstáculos, innovar con nuevos aprendizajes y establecer planes de acción ante posibles riesgos. En la importancia del gobierno de datos, es válido resaltar que, su organización o aplicabilidad depende de los contextos de las entidades; sin embargo, suele ser flexible, pero con elementos directivos de seguridad, calidad, agilidad en el almacenamiento y los expertos que se encargarán del circuito deberán tener profesionalismo, experiencia y compromiso.
Lo expuesto, genera una reflexión autónoma como participativa, que se centraliza en que el gobierno del dato permite el crecimiento de las organizaciones, los mantiene en el auge tecnológico y en la competencia, sin olvidar las necesidades del cliente.
Para organizaciones mundiales como IBM, la gestión de los datos brinda la oportunidad de flexibilizar las estrategias, tener analítica en la confianza, determinar la privacidad, seguridad, gestión de la información y sobre todo la catalogación inteligente del dato.
El gobierno del dato facilita una accesibilidad, trasformación, la actualización rápida y la operacionalización dinámica en las necesidades o quehaceres diarias de las entidades, pero, sus múltiples ventajas dependerán de las cualidades de las empresas de forma independiente y los objetivos que se tracen desde la visión panorámica de un proceso continuo y permanente (Lurillo, 2020).
Gobierno del dato
El Gobierno del dato permite a las organizaciones tomar mejores decisiones, ajustarse a la calidad, custodiar y seguir circuitos con la participación de todos los proyectos para tener exitosos resultados.
El gobierno del dato en sus muchas oportunidades y capacidades se caracteriza por tener un foco específico en el aprovechamiento de la tecnología por el uso de programas que permiten la agilidad y la gobernanza; además de tener una eficiencia de valor TI, tener mejor impacto productivo y dar soluciones ante problemáticas del entorno.
Otra de las características que priman en el gobierno del dato es el conocimiento específico del mismo y su uso transformacional con calidad, transparencia y migración. Entonces, ante las realidades y novedades de los datos, las organizaciones deben estar al día y adoptar las anteriores variables.
El gobierno del dato se encuentra en diferentes sectores de la misma organización como por ejemplo la arquitectura de datos, la custodia, la ingesta y el tratamiento de disposición final; estos pasos suelen estar acompañados de sus procesos, equipos generalizados y profesionales expertos. Estas capacidades del gobierno parten de las demandas del contexto, de los proyectos, una identificación inicial, un análisis panorámico, el perfilamiento, la definición, gestión, despliegue de almacenamiento y aprovechamiento final para una gestión especifica en los sectores productivos, financieros o empresariales (Ministerio de Tecnologías de la Información y las Comunicaciones, 2014). |
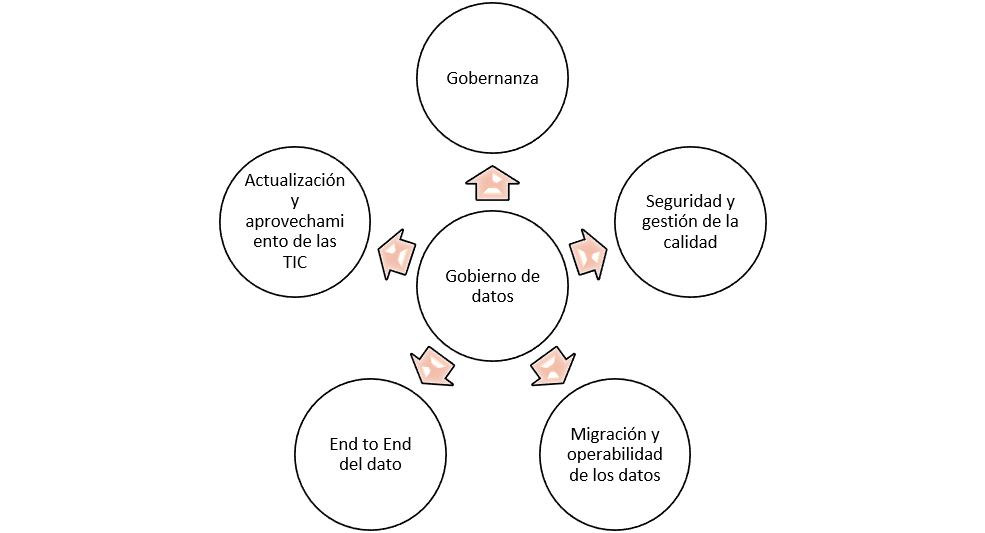
Acciones
En la transformación digital de las organizaciones
Escrito por Silvia Juliana Rueda Urrea
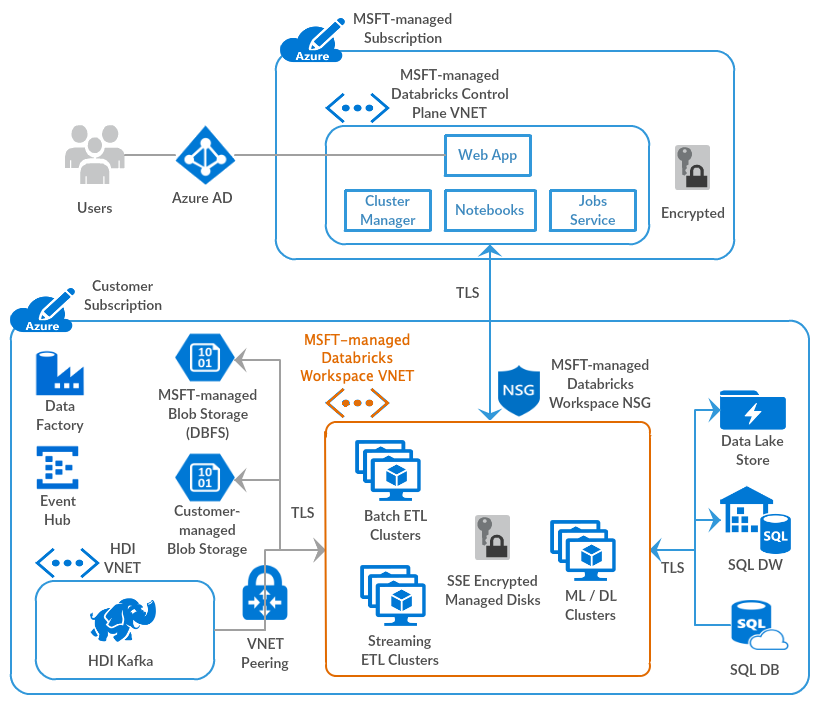
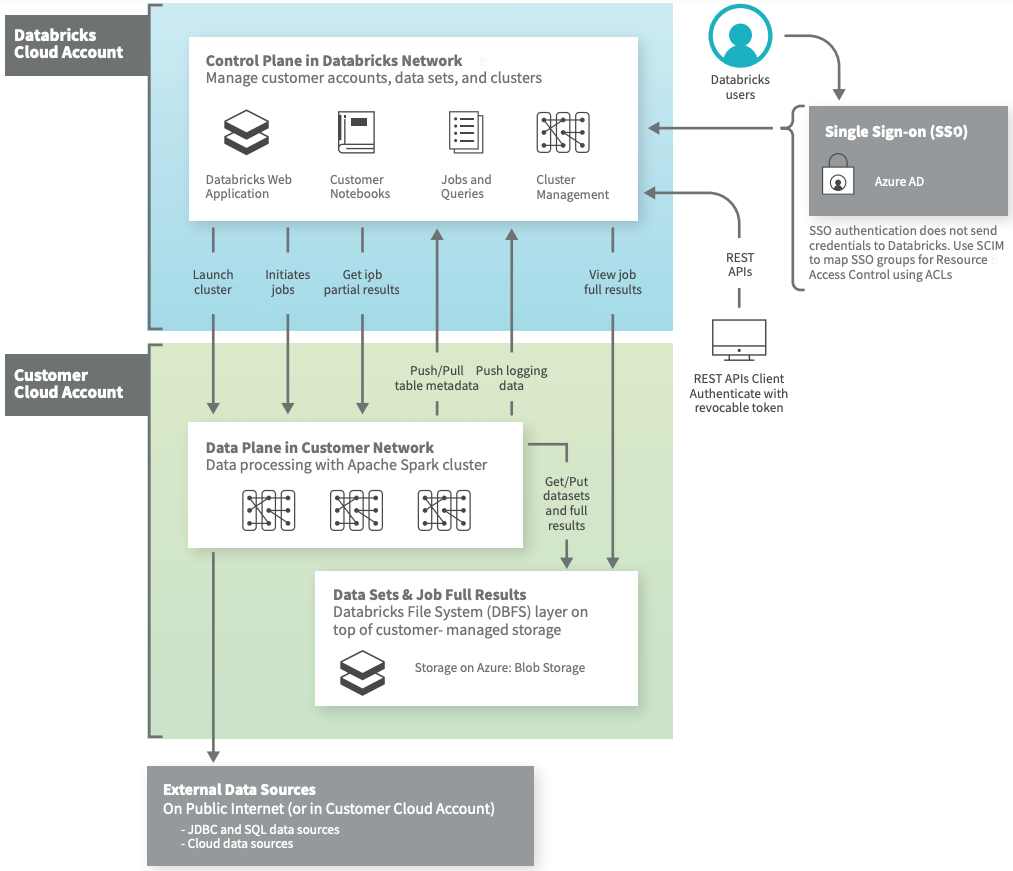
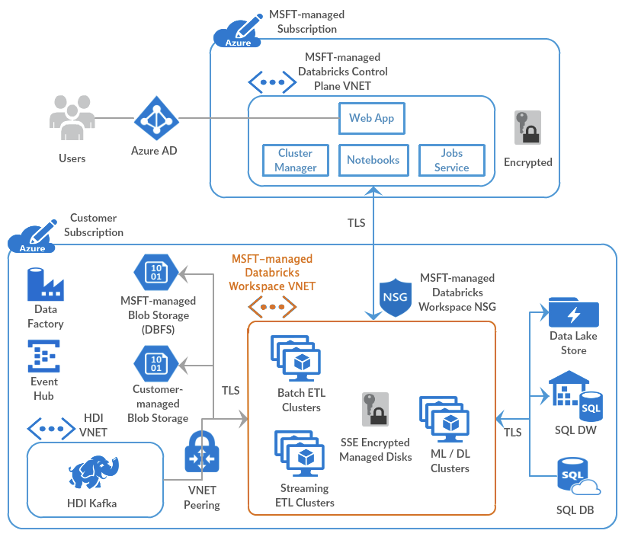
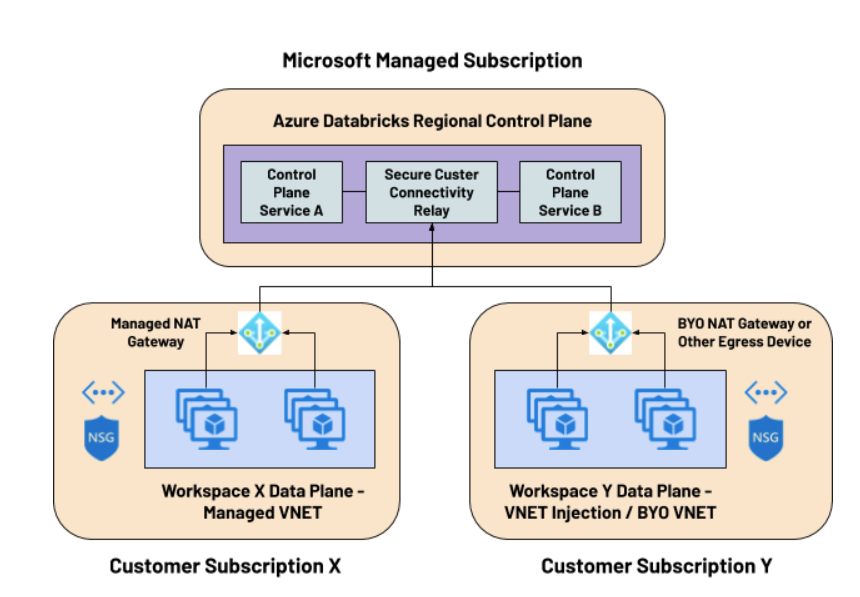
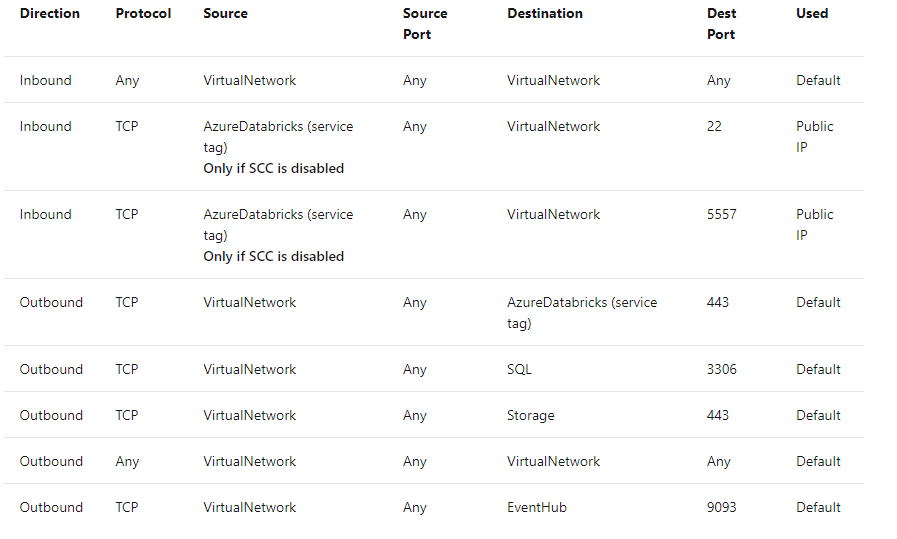
Ante las acciones y ejecuciones, las organizaciones pueden generar impactos con los elementos de la figura anterior, tales como la gobernanza, la seguridad, el afianzamiento de la calidad, la migración de los datos desde los sistemas orígenes a los repositorios finales, el ciclo de vida del dato y todo en relación con la actualización y estandarizaciones en novedades digitales. | En cada sentido y horizontalidad de la gestión de los datos, el equipo debe manejar sólidas metodologías para alcanzar los objetivos y buscar que el equipo pueda contribuir a las metas con sus capacidades, habilidades y destrezas individuales como colectivas.
|
En el camino tecnológico "un después de la pandemia”
Con relación a la situación de pandemia en todos los sectores se obtuvo una transformación significativa.

Con las necesidades de innovación por los cierres masivos de las organizaciones, estas aprovecharon los datos y el auge digital para impactar en su quehacer, reapertura y adaptarse a las realidades tecnológicas.
Respecto a las innovaciones, con el paso de los días se crean nuevos sistemas que apoyan la gestión de los datos y que permiten tener óptimos resultados en la gestión diaria de cada empresa.
Finalmente, la invitación es abierta a seguir en el camino del cambio, de la tecnología y del aprovechamiento de los datos que seguramente son el camino al futuro.
Referencias Bibliográficas
Lurillo, M. (2020). Actividades Claves en el diseño de una estrategia de Gobierno de Datos.
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
Silvia Juliana Rueda Urrea
Experienced Consultant
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar