Gobierno de Datos: ¿tendencia o necesidad?

Alvar Noe Arellanos
Business & IT Strategy Professional

En los últimos años la implementación de un gobierno de datos corporativo dentro de las diferentes organizaciones, independientemente de la industria a la que pertenezca. En cada una de estas implementaciones surge una pregunta recurrente “El Gobierno de Datos es una necesidad o una tendencia”. Realmente no es una pregunta fácil de contestar ya que deben considerarse varios aspectos para poder contestarla.
Con la llegada de la pandemia, las organizaciones tuvieron que evolucionar de manera acelerada a un esquema digital en el cual los datos, las personas, la escalabilidad de tecnología y la evolución de procesos, juegan un rol esencial para la evolución y trascendencia de las empresas
Si los datos se posicionan como un pilar esencial dentro de la evolución de las organizaciones, tiene sentido que el control y aprovechamiento total de estos requiera la necesidad de un gobierno de datos.
El Gobierno de Datos, según el marco metodológico DAMA®, es definido de la siguiente forma:
"El ejercicio de autoridad compartida, control y toma de decisiones (planificación, seguimiento y aplicación) a través de la gestión de los activos de datos"

Hasta este momento hemos identificado que el Gobierno de Datos es necesario para la evolución de una organización, aun no determinamos en que aspectos se estaría se centraría. Estos aspectos los listamos a continuación:
Organización
Colaboradores que interactúan en la gestión y administración de los activos de datos de la empresa relacionados con el Gobierno de Datos.
Procesos
Las tareas y actividades que conforman los procesos de gestión del Gobierno de Datos
Políticas y Estándares
Las políticas, estándares y lineamientos que permitan gestionar, controlar y estandarizar el Gobierno de Datos.
Tecnología
Tecnología, arquitectura, herramientas que se utilizan para la administración de la información relacionada con el Gobierno de Datos
Si bien estos pilares del Gobierno de Datos permitirán que los datos soporten la evolución digital de la organización, es importante aclarar que para que esto funcione es necesario mantener un modelo alineado a la estrategia de negocio, que sea sustentable y flexible, permitiendo identificar y ajustar de forma activa nuevas fuentes de información, SLAs, entre otros requerimientos que soporten los objetivos de negocio.
Con la implementación de un Gobierno de Datos dentro de las organizaciones se podrán obtener beneficios asociados directamente a las áreas de negocio, por ejemplo:
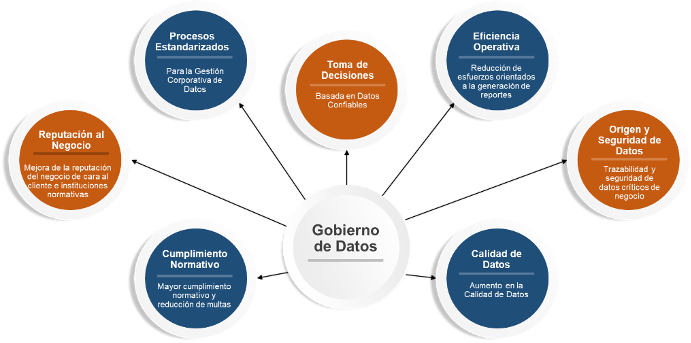
La obtención de estos beneficios permitirá que la evolución de las organizaciones frente a los retos globales y de las industrias, sea posible.
Dicho lo anterior se pude inferir que el gobierno de datos configura la gestión general de la disponibilidad, usabilidad, integridad y seguridad de los datos usados en una organización, permitiendo a las organizaciones eliminar una administración ineficiente de la información que afectaría a las organizaciones. Especialmente si miramos desde la perspectiva financiera y consideramos que el flujo de datos ha aumentado de forma exponencial en los últimos años a raíz del desarrollo de nuevas tecnologías y del crecimiento del mercado.
Tener una buena gestión de datos significa tomar las mejores decisiones para el negocio, lo que resulta en el aumento de la productividad y de la eficiencia operacional y, consecuentemente, en un incremento en los ingresos empresariales.
Una vez identificada la importancia y los beneficios que el gobierno de datos puede presentar podemos llegar a la conclusión que la implementación de un Gobierno de Datos dentro de una empresa que esta evolucionando a una cultura digital y data driven, es necesaria y no solo una tendencia a implementar según la industria a la cual la organización pertenece.
Alvar Noe Arellanos
Business & IT Strategy Professional
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar