FinOps
La Ingeniería del Ahorro en la Era de la Nube y como aplicarlo funcional y técnicamente

Francis Josue De La Cruz
Big Data Architect
Wiener Morán
Data Engineer

En el mundo empresarial actual, la eficiencia en la gestión de costos en la nube se ha convertido en una prioridad. Aquí es donde entra en juego FinOps (Financial Operations), una práctica emergente que combina estratégicas presupuestales, la tecnología de la información (servicios en la nube), estrategias de negocios para maximizar el valor de la nube y sobretodo la inventiva y desarrollo para tratar de sacar provecho económico. En este artículo queremos compartir desde Bluetab, cómo nuestros clientes pueden implementar FinOps, con un enfoque particular en los servicios de Azure de Microsoft.
Estos servicios en la nube brindan una poderosa flexibilidad en la construcción de soluciones y hacen realidad la meta común de pasar del CAPEX al OPEX. Esto se enfrenta al nuevo desafío que las empresas ahora tienen, de monitorear cientos o miles de recursos a la vez para mantener las finanzas alineadas a los presupuestos tecnológicos definidos. Una buena (y necesaria) práctica para esto, es el monitoreo activo de los recursos y costos cloud, lo que permite identificar oportunidades de optimización de recursos no utilizados o infrautilizados, para aplicar los cambios de configuración, prendido y apagado oportuno que pueden conllevar a una significativa reducción de costos.
¿Qué es FinOps?
FinOps es un enfoque, paradigma cultural y operativo que permite a las organizaciones equilibrar y alinear mejor los costos con el valor en entornos de nube. Se trata de una práctica colaborativa, que involucra a equipos de finanzas, operaciones y desarrollo, para gestionar los costos de la nube de manera más efectiva y eficiente.
¿En qué etapa del proyecto se debe considerar el FinOps?
El FinOps, o la gestión financiera de la nube, se debe considerar desde las primeras etapas de un proyecto que involucra servicios en la nube, ya que ayuda a entender y optimizar los costos asociados.
No siempre demanda tener un equipo dedicado desde el inicio, especialmente en proyectos pequeños o medianos, pero sí requiere que alguien asuma la responsabilidad de monitorear y optimizar los costos. A medida que el proyecto crece y el gasto en la nube se incrementa, puede ser beneficioso establecer un equipo dedicado o función de FinOps para gestionar estos costos de manera más efectiva.
Pasos para Implementar FinOps en una empresa usando Servicios de Azure

1. Comprensión y adopción de la cultura FinOps
Educación y Conciencia: capacite a su equipo sobre los principios de FinOps. Esto incluye entender cómo el gasto en la nube afecta a la empresa y cómo pueden contribuir a una gestión más eficiente.
Combinando la Agilidad (Scrum-finOps) en la empresa
Es posible combinar el framework scrum con el enfoque FinOps agregando nuevas ceremonias enfocadas en el mismo, con la finalidad de implementar nuevas prácticas de comunicación y gestión. Por ejemplo, reuniones semanales donde se presentan como va el presupuesto del proyecto y reuniones diarias de cómo va el consumo de los servicios en los diferentes ambientes (development, quality assurance y production).
Colaboración interdepartamental: fomente la colaboración entre los equipos de finanzas, operaciones y desarrollo. La comunicación efectiva es clave para el éxito de FinOps.
2. Análisis del gasto actual en Azure
Auditoría de servicios: realice un inventario de todos los servicios de Azure utilizados. Comprenda cómo se están utilizando y si son esenciales para las operaciones comerciales.
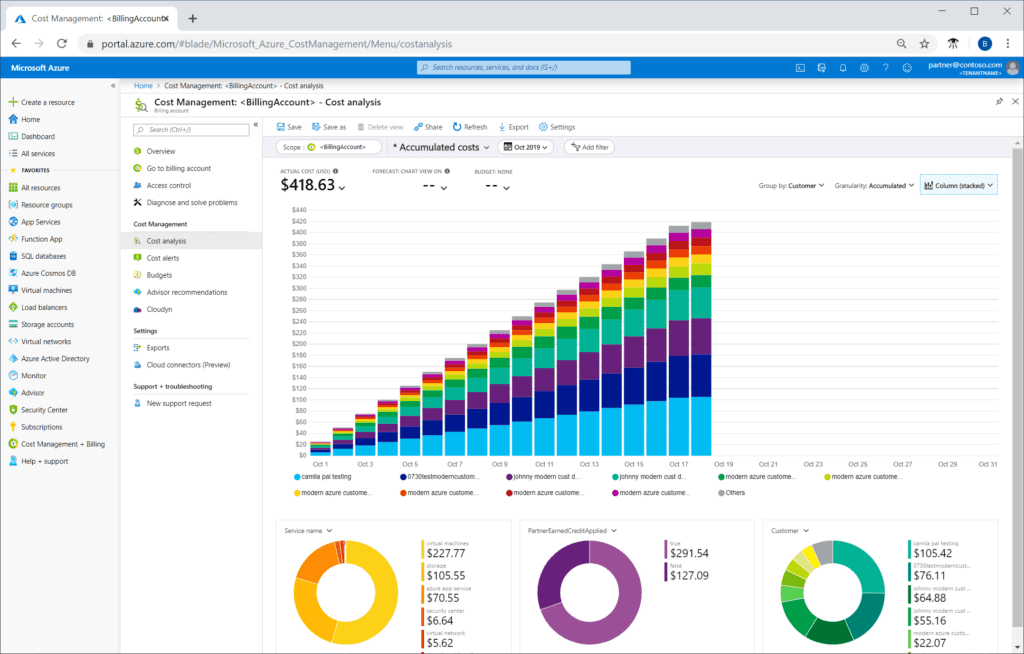
Herramientas de gestión de costos: utilice herramientas como Azure Cost Management y Billing para obtener una visión clara del gasto.
3. Optimización de recursos y costos
Identificación de recursos subutilizados: busque instancias, almacenamiento o servicios que estén infrautilizados. Azure ofrece herramientas para identificar estos recursos.
Implementación de mejores prácticas: aplique prácticas recomendadas para la optimización de recursos, como el escalado automático, la elección de instancias reservadas o el apagado de recursos no utilizados.
3. Optimización de recursos y costos
Establecimiento de presupuestos: defina presupuestos claros para diferentes equipos o proyectos. Azure Cost Management puede ayudar en este proceso.
Pronósticos de gasto: antes de empezar el desarrollo de ahorro de costos en una empresa, se debe tener claro el uso y gasto actual, para estimar el ahorro proyectado. Imagínese cuanto ahorraría en una empresa con más de diez mil pipelines.
Ejemplo: estrategias de ahorro de costos de migración All-purpose hacia Job Clusters en 1 aplicación realtime (13,5 horas prendidas) ahorro de 44% aproximadamente.
| Tipos | Dbu/hora | #DBU/hora | Horas activas RT | #Clusters | Total diario | Total mensual | Total Anual |
|---|---|---|---|---|---|---|---|
| Job Cluster-REALTIME | $0,30 | 3,75 | 13,5 | 1 | $15,19 | $455,63 | $5.467,50 |
| All Purpose-REALTIME | $0,55 | 3,75 | 13,5 | 1 | $27,84 | $835,31 | $10.023,75 |
5. Gobernanza y políticas de uso
Políticas de uso: establezca políticas claras para el uso de recursos en Azure. Esto incluye quién puede aprovisionar recursos y qué tipos de recursos están permitidos.
Automatización de la gobernanza: implemente políticas automatizadas para garantizar el cumplimiento y evitar gastos innecesarios.
Comparativa de características de servicios de gobernanza de costos:
| Google Cost Management | AWS Cost Management | Microsoft Cost Management | |
|---|---|---|---|
| Informes y paneles de control | Visualización de informes de costos, personalización mediante Looker Studio. | Proporciona informe de gastos y sus detalles (AWS Cost Explorer) | Reportes y análisis de la organización. Extensible el análisis con Power BI. |
| Control de Acceso | Uso de políticas para permisos granulares y nivel de jerarquía. Puede establecer quien visualiza los costos y quien realiza los pagos. | Permite establecer mecanismos de gobernanza y seguimiento de la información de facturación en la organización | Control de acceso basado en roles de Azure RBAC. Los usuarios con Azure Enterprise usan una combinación de permisos del Azure Portal y Enterprise (EA) |
| Presupuesto y alertas | Configuración de presupuestos que envíen alerta por correo si se supera el umbral. | Presupuestos con notificaciones de alerta automáticas (AWS Budgets) | Las vistas de presupuestos pueden estar limitadas por suscripción, grupos de recursos o colección de recursos. Soporta alertas. |
| Recomendaciones | Recomendaciones inteligentes para optimizar costos, las cuales son fácilmente aplicables. | Alinea el tamaño de los recursos asignados con la demanda real de la carga de trabajo (Rightsizing Recommendations) | Optimizaciones de costos según recomendaciones usando Azure Advisor. |
| Cuotas | Configuracion de limites de cuotas, que restringe la cantidad de recursos que se pueden utilizar. | Mediante el Service Quotas, limitan los servicios siendo los valores máximos para los recursos. | Dispone de diferentes clasificaciones de límites, algunos de ellos: generales, grupo de administración, suscripción, grupo de recursos, plantilla. |
6. Desarrollo e innovación
Ahorro de Costos con el Despliegue de Job Clusters en Databricks
En el mundo de la ciencia de datos y el análisis de grandes volúmenes de datos, Databricks se ha establecido como una plataforma líder. Una de las características clave de Databricks es su capacidad para manejar diferentes tipos de clústeres, siendo los más comunes los «All-Purpose Clusters» y los «Job Clusters». En este artículo, nos centraremos en cómo el despliegue de Job Clusters puede ser una estrategia efectiva para ahorrar costos, especialmente en comparación con los All-Purpose Clusters.
Diferencia entre All-Purpose Clusters y Job Clusters
Antes de sumergirnos en las estrategias de ahorro de costos, es crucial entender la diferencia entre estos dos tipos de clústeres:
All-Purpose Clusters: están diseñados para ser utilizados de manera interactiva y pueden ser compartidos por varios usuarios. Son ideales para el desarrollo y la exploración de datos.
Job Clusters: se crean específicamente para ejecutar un trabajo y se cierran automáticamente una vez que el trabajo ha finalizado. Son ideales para trabajos programados y procesos automatizados. La desventaja en el entorno de Azure de este tipo de despliegue de cluster es que al ser más barato no tiene funciones de gestión de control de uso.
Ejemplo Despliegue Job Cluster
# Configuración de Databricks API
DATABRICKS_INSTANCE = 'https://tu-instancia-databricks.com'
TOKEN = 'tu-token-de-acceso'
JOB_ID = 'tu-job-id'
# Headers para la autenticación
HEADERS = {
'Authorization': f'Bearer {TOKEN}'
}
# Verificar el estado del job
def check_job_status(job_id):
response = requests.get(f'{DATABRICKS_INSTANCE}/api/2.0/jobs/get?job_id={job_id}', headers=HEADERS)
if response.status_code == 200:
return response.json()['state']
else:
raise Exception("Error al obtener el estado del job")
# Cancelar el job si está en ejecución
def cancel_job(job_id):
response = requests.post(f'{DATABRICKS_INSTANCE}/api/2.0/jobs/runs/cancel', json={"job_id": job_id}, headers=HEADERS)
if response.status_code != 200:
raise Exception("Error al cancelar el job")
# Desplegar el job
def deploy_job(job_id):
response = requests.post(f'{DATABRICKS_INSTANCE}/api/2.0/jobs/run-now', json={"job_id": job_id}, headers=HEADERS)
if response.status_code == 200:
return response.json()['run_id']
else:
raise Exception("Error al desplegar el job")
# Verificar si el job está corriendo y esperar hasta que lo esté
def wait_for_job_to_run(job_id):
while True:
status = check_job_status(job_id)
if status['life_cycle_state'] == 'RUNNING':
print("El job está corriendo.")
break
elif status['life_cycle_state'] == 'TERMINATED':
print("El job ha terminado o ha sido cancelado.")
break
elif status['life_cycle_state'] == 'PENDING':
print("El job está pendiente de ejecución, esperando...")
time.sleep(10) # Esperar un tiempo antes de volver a verificar
else:
raise Exception(f"Estado del job desconocido: {status['life_cycle_state']}")
# Script principal
if __name__ == '__main__':
# Verificar si el job está actualmente en ejecución y cancelarlo si es necesario
try:
status = check_job_status(JOB_ID)
if status['life_cycle_state'] == 'RUNNING':
print("Cancelando el job en ejecución...")
cancel_job(JOB_ID)
except Exception as e:
print(f"Error al verificar o cancelar el job: {e}")
# Desplegar el job
try:
print("Desplegando el job...")
run_id = deploy_job(JOB_ID)
print(f"Job desplegado con run_id: {run_id}")
except Exception as e:
print(f"Error al desplegar el job: {e}")
# Esperar a que el job esté en 'RUNNING'
try:
wait_for_job_to_run(JOB_ID)
except Exception as e:
print(f"Error al esperar que el job esté corriendo: {e}")
Automatización y programación Cosmos DB:
Automatizar y programar un script para reducir al mínimo los Request Units (RU/s) en Azure Cosmos DB puede ayudar a optimizar los costos, especialmente durante los períodos de baja demanda o basándose en métricas de rendimiento o un horario predefinido. Puedes hacer esto usando PowerShell o Python primero debes obtener el throughput actual (RU/s configuradas) del contenedor y luego calcular el 1% de este valor para establecer el nuevo throughput. A continuación, un ejemplo básico en ambos lenguajes.
Usando PowerShell
from azure.cosmos import CosmosClient
import os
# Configuración de Azure Cosmos DB
URL = os.environ.get('AZURE_COSMOS_DB_URL')
KEY = os.environ.get('AZURE_COSMOS_DB_KEY')
DATABASE_NAME = 'tuBaseDeDatos'
CONTAINER_NAME = 'tuContenedor'
# Inicializar cliente de Cosmos DB
client = CosmosClient(URL, credential=KEY)
database = client.get_database_client(DATABASE_NAME)
container = database.get_container_client(CONTAINER_NAME)
# Obtener el throughput actual
throughput_properties = container.read_throughput()
if throughput_properties:
current_ru = throughput_properties['throughput']
min_ru = max(int(current_ru * 0.01), 400) # Calcula el 1%, pero no menos de 400 RU/s
# Actualizar RU/s
try:
container.replace_throughput(min_ru)
except Exception as e:
print(f"Error al actualizar RU/s: {e}")
Usando Python para reducir RUS bajo demanda o horario de bajo rendimiento
from azure.cosmos import CosmosClient
import os
from datetime import datetime
# Configuración de Azure Cosmos DB
URL = os.environ.get('AZURE_COSMOS_DB_URL')
KEY = os.environ.get('AZURE_COSMOS_DB_KEY')
DATABASE_NAME = 'tuBaseDeDatos'
CONTAINER_NAME = 'tuContenedor'
# Inicializar cliente de Cosmos DB
client = CosmosClient(URL, credential=KEY)
database = client.get_database_client(DATABASE_NAME)
container = database.get_container_client(CONTAINER_NAME)
# Obtener la hora actual
current_hour = datetime.now().hour
# Definir RU/s según la hora del día
if 0 <= current_hour < 7 or 18 <= current_hour < 24:
new_ru = 400 # RU/s más bajas durante la noche
else:
new_ru = 1000 # RU/s estándar durante el día
# Actualizar RU/s
container.replace_throughput(new_ru)
7. Monitoreo continuo y mejora
Revisiones regulares: realice revisiones periódicas del gasto y la utilización de recursos.
Ajustes y mejoras: esté dispuesto a ajustar políticas y prácticas según sea necesario para mejorar continuamente la eficiencia del gasto.
Capacitación y conciencia continua
Un factor diferencial de este tipo de servicios y acompañamiento a nuestros socios tecnológicos es la posibilidad de descubrir, probar a escala y medir objetivamente los beneficios de cada plan de optimización de recursos y costos en sus plataformas, mismo que se plantea como resultado de una revisión regular, proactiva y basada en los cambios liberados por los proveedores de nube.
En Bluetab estamos comprometidos con el ahorro y nuestros especialistas en administración de datos con gusto podrán ayudarte a alcanzar niveles eficientes de monitoreo de costos, servicios y consumo en nubes, que apalanquen tu inversión tecnológica y gastos de operación.
7. Monitoreo continuo y mejora
Implementar FinOps en una empresa que utiliza servicios de Azure no es solo una estrategia para reducir costos, sino una transformación cultural y operativa. Requiere un cambio en la forma en que las organizaciones piensan y actúan respecto al uso de la nube.
Al adoptar FinOps, las empresas pueden no solo optimizar sus gastos en la nube, sino también mejorar la colaboración entre equipos, aumentar la agilidad y fomentar una mayor innovación.
Francis Josue De La Cruz
Big Data Architect
Wiener Morán
Data Engineer
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar