De documentos en papel a datos digitales con Fastcapture y Generative AI

Resumen
Los avances en Generative AI y en los grandes modelos de lenguaje, LLMs por sus siglas en inglés (Large Language Models), permiten transferir el pre-entrenamiento de estos modelos en una tarea simple, como predecir las palabras que faltan en una frase a tareas más complejas, como procesar documentos en papel para extraer sus datos de forma automática. Esta transferencia del entrenamiento funciona tan bien que es posible plantear desarrollar casos de uso que cierren el gap entre la digitalización y las actividades que requieren documentos en papel.
Hemos desarrollado un proyecto para modernizar la tecnología de AI de Fastcapture, nuestro IDP (Intelligent Document Processing), con Generative AI y LLMs. Hemos conectado Fastcapture con Hugging Face, un hub de la comunidad Open Source de AI. Los resultados que hemos obtenido están muy por encima de un F1 score de 0.9.
Introducción
Estamos viviendo una era de disrupciones. Esta situación está produciendo un momento de constantes avances tecnológicos. Me voy a fijar en 2 de ellos, la digitalización y el desarrollo de aplicaciones con inteligencia artificial (AI).
La pandemia COVID-19 ha sido terrible. Ahora bien, una de sus consecuencias ha sido la aceleración de la digitalización. El crecimiento de usuarios digitales ha sido de 2 dígitos en la gran mayoría de las empresas. Sin embargo, muchas actividades en las empresas siguen requiriendo documentos en papel. Un informe del US Bureau of Labor Statistics indica que las compañías americanas se gastaron $5,3Bn en cargar manualmente los documentos durante el año 2021.
Los avances en AI, y en particular los avances en Generative AI y en los grandes modelos de lenguaje han alcanzado un momento que, a parte de la aparición de aplicaciones sorprendentes como ChatGPT, permite el desarrollo de casos de uso de tratamiento de textos e imágenes con unos niveles de precisión muy elevados >0.9.
Juntando estas piezas, hoy es realmente posible plantear automatizar el procesamiento de documentos en papel a escala para convertirlos en datos digitales listos para ser consumidos y analizados en cualquier otra actividad de la empresa.
El problema
Muchas actividades en las empresas siguen requiriendo documentos en papel. Facturas, contratos, informes. Estos documentos contienen datos relevantes y disponer de una versión digital es clave para la digitalización de las empresas.
Una forma de convertir los documentos en papel en datos digitales es mediante cargas manuales. También se pueden convertir en datos digitales utilizando aplicaciones del tipo de un IDP. Un IDP consiste en un grupo de pipelines con pasos para procesar los documentos y convertirlos en datos digitales. El primer paso es la conversión del documento en texto con un modelo OCR (Optical Character Recognition).
A continuación vienen los pasos para tratar el texto. Los pasos de tratamiento del texto pueden utilizar modelos de AI. Típicamente estos modelos de AI están basados en una arquitectura RNN (Recurrent Neural Network). Los modelos RNN tratan la secuencia de palabras en orden, una a una. Estos modelos se enfrentan a 2 dificultades a la hora de realizar su tarea. La primera es su capacidad de tratamiento del contexto. Según se van alejando las palabras y las frases, el modelo empieza a perder su capacidad para relacionarlas. La segunda es la dificultad que tienen para escalar y, por lo tanto, para ser entrenados en grandes volúmenes de textos. Estas 2 dificultades suponen un techo para la precisión del IDP y por lo tanto para su capacidad de automatizar la conversión de documentos en papel en datos digitales.
La solución propuesta
Los LLM se basan en la arquitectura de los Transformers. Esta arquitectura propuesta en el paper “Attention is all you need” Vaswani et al. 2017 fué totalmente revolucionaria. Trata la secuencia a través del mecanismo de atención mediante matrices. El mecanismo de atención permite realizar un mejor procesamiento del contexto.
Todas las palabras se encuentran a la misma distancia entre sí medida en número de operaciones matemáticas. Y permite escalar el entrenamiento de forma horizontal. Los modelos basados en esta arquitectura se pueden entrenar con cantidades de textos muy grandes.
En el paper “Improving Language Understanding by Generative Pre-Training” Radford et al. 2018 proponen un nuevo framework de 2 fases para entrenar los LLMs. Un pre-entrenamiento no supervisado sobre un objetivo sencillo, predecir la siguiente palabra de un texto, y con grandes volúmenes de textos. Y un fine-tune para adaptar el modelo a resolver una tarea NLP concreta como extraer datos relevantes de un documento, y con pocos ejemplos.
Esta combinación es ideal para transferir el pre-entrenamiento de un modelo con grandes cantidades de textos a tareas para las que se disponen de pocos ejemplos.
Nuestra aproximación consiste en utilizar LLMs pre-entrenados disponibles en la comunidad Open Source y realizar un fine-tune para convertir los documentos en papel en datos digitales.
Hemos conectado nuestro IDP Fastcapture con el hub de Hugging Face donde residen LLMs pre-entrenados Open Source para acceder a ellos y generar versiones especializadas mediante un fine-tune en nuestro hub privado sin enviar los datos al hub público.
Cómo incorporar los LLMs en un IDP
La estrategia que hemos seguido para incorporar los LLMs en nuestro IDP Fastcapture se ha basado en 3 pilares, aprender a través de I+D, apoyarnos en la comunidad Open Source de AI y construir sobre lo que ya teníamos.
Estos han sido los pasos clave del proyecto:
- La selección del LLM pre-entrenado
- El diseño del contexto del Transformer
- Utilizar entornos multi-GPU para realizar el fine-tune y el servicing
La selección del LLM pre-entrenado
La comunidad Open Source de AI da acceso a LLMs pre-entrenados con un nivel de calidad enterprise-grade. Nuestro caso de uso requiere un modelo tipo encoder con capacidades multi idioma. De esta manera un único modelo será capaz de extraer datos relevantes de documentos del mismo tipo con diferente idioma.
Nos decantamos por el modelo pre-entrenado XLM-R propuesto en el paper “Unsupervised Cross-lingual Representation Learning at Scale” Conneau et al. 2020. El modelo XLM-R ha sido pre-entrenado en 2.5TB de textos con 100 idiomas. Hemos utilizado las siguientes tallas:
Modelo | Número de parámetros |
XLM-RLarge | 550M |
XLM-RXL | 3.5B |
Diseño del contexto del Transformer
Diseñar cómo usar el contexto del LLM es un factor importante a la hora de conseguir niveles de performance de 0.9.
Los documentos están organizados en páginas y frases. Lo que queremos es que el LLM analice frase a frase en búsqueda de datos relevantes. Los tipos de documentos que manejamos son más bien telegráficos, con poco texto. Esto suele ser una tónica habitual al tratar documentos en papel en el mundo empresarial.
Para dar una mejor oportunidad al LLM de hacer su tarea ubicamos la frase de interés a la derecha del contexto y completamos el contexto por la izquierda con las frases predecesoras que quepan.
El siguiente esquema muestra el diseño al que nos referimos.
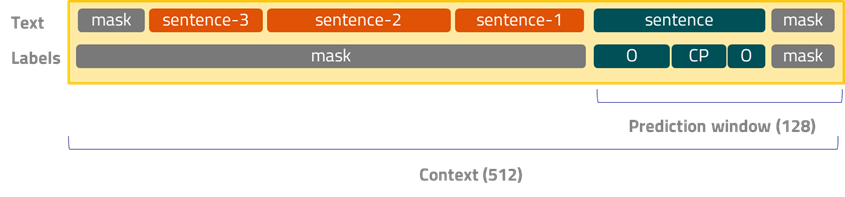
Fine-tune y servicing en un entorno multi-GPU
Realizar un fine-tune de un LLM requiere utilizar GPU’s (Graphics Processing Units). El modelo XLM-RLarge puede entrenarse sin utilizar un framework que optimice el uso de la memoria o que distribuya el modelo entre diferentes GPUs.
Sin embargo la versión XLM-RXL es tan grande que al realizar el algoritmo de gradient descent no cabe y requiere utilizar frameworks de optimización y/o que distribuyan el modelo en el entorno multi-GPU.
El proyecto lo hemos realizado en una máquina virtual con 4 GPUs NVIDIA a10g, y hemos utilizado el framework propuesto en el paper “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models” Rajbhandari et al. 2020. ZeRO optimiza el uso de la memoria para almacenar el estado del modelo a la hora de entrenar y permite distribuir los gradientes y los parámetros entre las GPUs.
Utilizar entornos multi-GPU y frameworks de optimización como ZeRO, a parte de poder escalar el proceso de fine-tuning, permite gestionar los recursos computacionales que requieren modelos extra grandes.
Resultados
En el proyecto hemos utilizado 2 juegos de datos, uno de factura y otro de informes económicos.
El impacto de la talla en el performance depende del caso de uso
Las siguientes gráficas muestran el F1 score de las 2 tallas, L y XL, en cada uno de los juegos de datos.
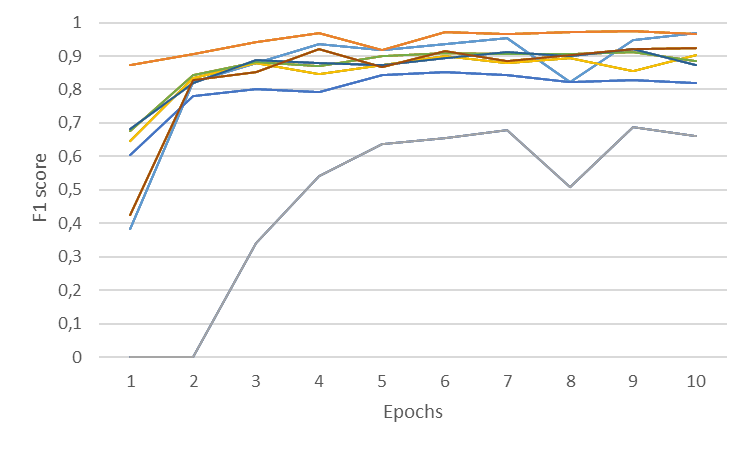
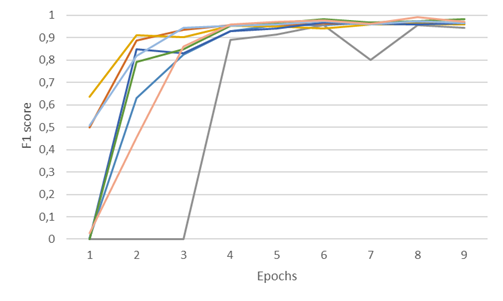
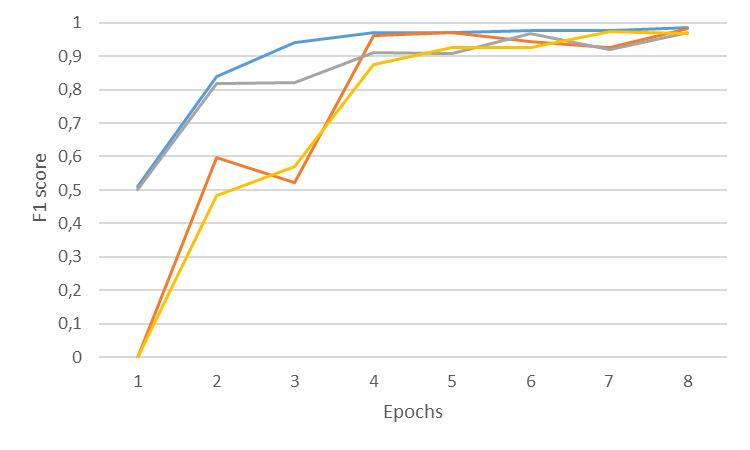
Estas gráficas ayudan a visualizar la diferencia de performance entre las tallas L y XL en los 2 juegos de datos y poder decidir qué modelo utilizar en el IDP. En el caso de las facturas la talla XL obtiene un score medio 8 puntos básicos mejor que la talla L, mientras que en el caso de los informes económicos la diferencia del score medio es de 1 punto básico.
Al elegir el tamaño de modelo adecuado para cada caso de uso hay que considerar varios factores como el performance del modelo, los recursos de computación y el trade-off entre precisión y complejidad. En algunos casos, un modelo más pequeño puede proporcionar resultados suficientemente precisos con menores requisitos de computación y menor complejidad de mantenimiento.
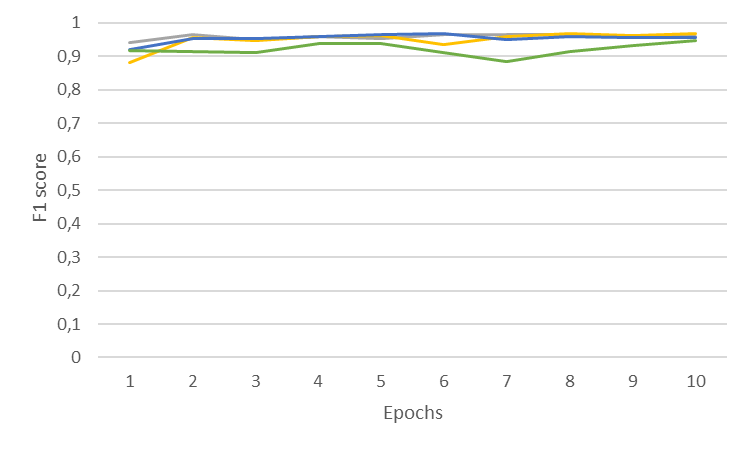
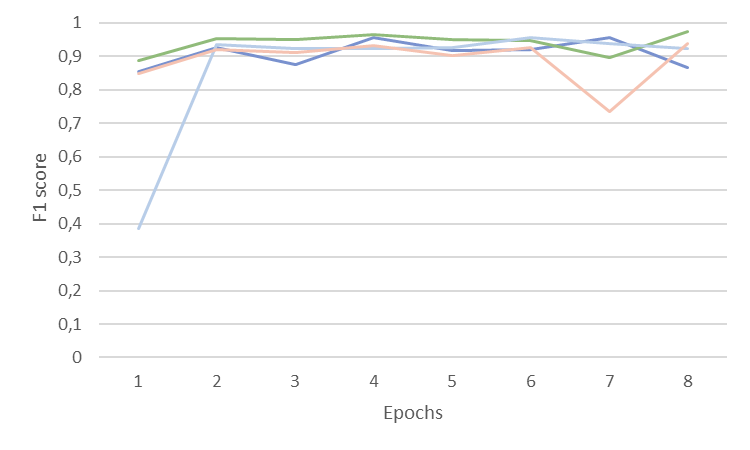
La importancia de diseñar el contexto al trabajar con LLMs
El diseño del contexto es clave para cualquier caso de uso con LLMs. La siguiente gráfica muestra el resultado de un fine-tune del modelo XLM-RLarge sin utilizar el contexto con diseño de ventana. El F1 score medio es 3 puntos básicos inferior sin utilizar el diseño de contexto con ventana.
Referencias
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. arXiv:1706.03762
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever. Improving Language Understanding by Generative Pre-Training. 2018.
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzman, Edouard Grave, Myle Ott, Luke Zettlemoyer, Veselin Stoyanov. Unsupervised Cross-lingual Representation Learning at Scale. 2020. arXiv:1911.02116v2.
Samyam Rajbhandari∗ , Jeff Rasley∗ , Olatunji Ruwase, Yuxiong He. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. 2020. arXiv:1910.02054v3
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar





