Cómo depurar una Lambda de AWS en local

AWS Lambda es un servicio serverless mediante el que se puede ejecutar código sin necesidad de levantar ni administrar máquinas. Se paga solamente por el tiempo consumido en la ejecución (15 minutos como máximo).
El servicio dispone de un IDE simple, pero por su propia naturaleza no permite añadir puntos de ruptura para depurar el código. Seguro que algunos de vosotros os habéis visto en esta situación y habéis tenido que hacer uso de métodos poco ortodoxos como prints o ejecutar el código directamente en vuestra máquina, pero esto último no reproduce las condiciones reales de ejecución del servicio.
Para permitir depurar con fiabilidad desde nuestro propio PC, AWS pone a disposición SAM (Serverless Application Model).
Instalación
Los requisitos necesarios son (se ha usado Ubuntu 18.04 LTS):
- Python (2.7 ó >= 3.6)
- Docker
- IDE que se pueda enlazar a un puerto de debug (en nuestro caso usamos VS Code)
- awscli
Para instalar la CLI de AWS SAM desde AWS recomiendan brew tanto para Linux como macOS, pero en este caso se ha optado por hacerlo con pip por homogeneidad:
python3 -m pip install aws-sam-cli Configuración y ejecución
1. Iniciamos un proyecto SAM
sam init - Por simplicidad se selecciona “AWS Quick Start Templates” para crear un proyecto a través de plantillas predefinidas
- Se elige la opción 9 – python3.6 como el lenguaje del código que contendrá nuestra lambda
- Se selecciona la plantilla de “Hello World Example»
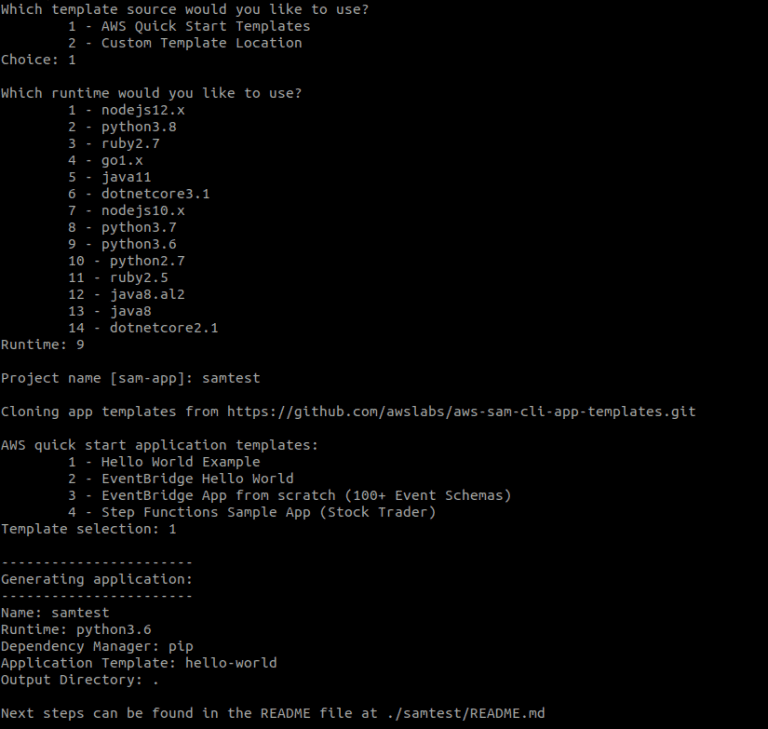
En este momento ya tenemos nuestro proyecto creado en la ruta especificada:
- /helloworld: app.py con el código Python a ejecutar y requirements.txt con sus dependencias
- /events: events.json con ejemplo de evento a enviar a la lambda para su ejecución. En nuestro caso el trigger será un GET a la API a http://localhost:3000/hello
- /tests : test unitario
- template.yaml: plantilla con los recursos de AWS a desplegar en formato YAML de CloudFormation. En esta aplicación de ejemplo sería un API gateway + lamba y se emulará ese despliegue localmente
2. Se levanta la API en local y se hace un GET al endpoint
sam local start-api Concretamente el endpoint de nuestro HelloWorld
será http://localhost:3000/hello Hacemos un GET
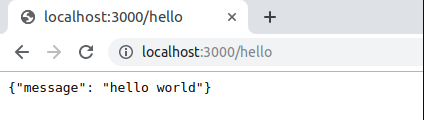
Y obtenemos la respuesta de la API
3. Añadimos la librería ptvsd (Python Tools for Visual Studio) para debugging a requirements.txt quedando como:
requests
ptvsd 4. Habilitamos el modo debug en el puerto 5890 haciendo uso del siguiente código en helloworld/app.py
import ptvsd
ptvsd.enable_attach(address=('0.0.0.0', 5890), redirect_output=True)
ptvsd.wait_for_attach() Añadimos también en app.py dentro de la función lambda_handler varios prints para usar en la depuración
print('punto de ruptura')
print('siguiente línea')
print('continúa la ejecución')
return {
"statusCode": 200,
"body": json.dumps({
"message": "hello world",
# "location": ip.text.replace("\n", "")
}),
} 5. Aplicamos los cambios realizados y construimos el contenedor
sam build --use-container 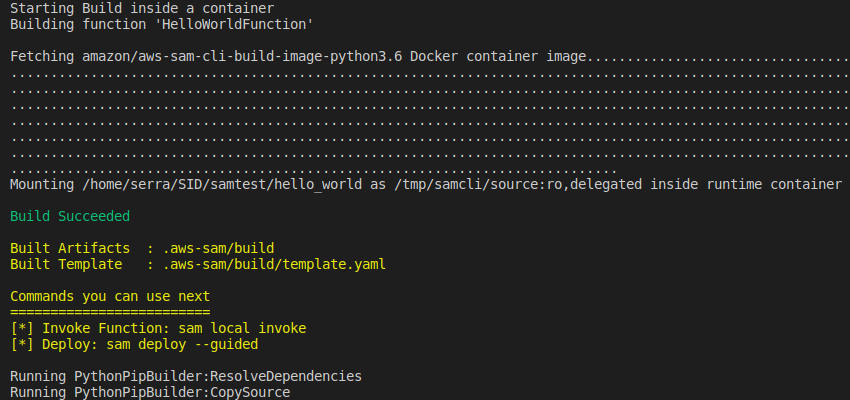
6. Configuramos el debugger de nuestro IDE
En VSCode se utiliza el fichero launch.json. Creamos en la ruta principal de nuestro proyecto la carpeta .vscode y dentro el fichero
{
"version": "0.2.0",
"configurations": [
{
"name": "SAM CLI Python Hello World",
"type": "python",
"request": "attach",
"port": 5890,
"host": "127.0.0.1",
"pathMappings": [
{
"localRoot": "${workspaceFolder}/hello_world",
"remoteRoot": "/var/task"
}
]
}
]
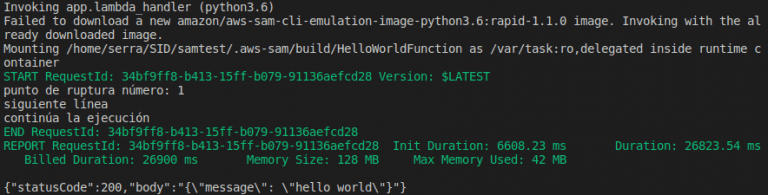
} 7. Establecemos un punto de ruptura en el código en nuestro IDE

8. Levantamos nuestra aplicación con la API en el puerto de debug
sam local start-api --debug-port 5890 9. Hacemos de nuevo un GET a la URL del endpoint http://localhost:3000/hello
10. Lanzamos la aplicación desde VSCode en modo debug, seleccionando la configuración creada en launch.json

Y ya estamos en modo debug, pudiendo avanzar desde nuestro punto de ruptura

Alternativa: Se puede hacer uso de events/event.json para lanzar la lambda a través de un evento definido por nosotros
En este caso lo modificamos incluyendo un solo parámetro de entrada:
{
"numero": "1"
} Y el código de nuestra función para hacer uso del evento:
print('punto de ruptura número: ' + event["numero"]) De esta manera, invocamos a través del evento en modo debug:
sam local invoke HelloWorldFunction -d 5890 -e events/event.json Podemos ir depurando paso a paso, viendo como en este caso se hace uso del evento creado:

¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar



























