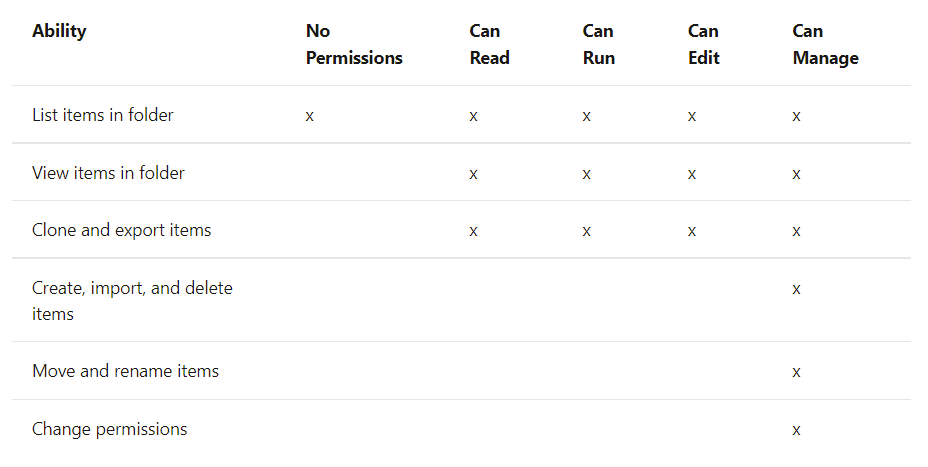
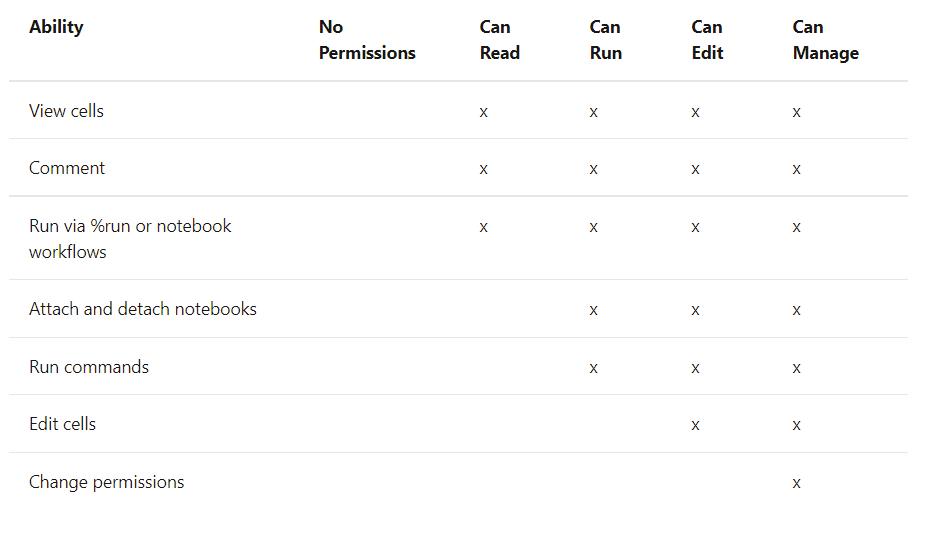
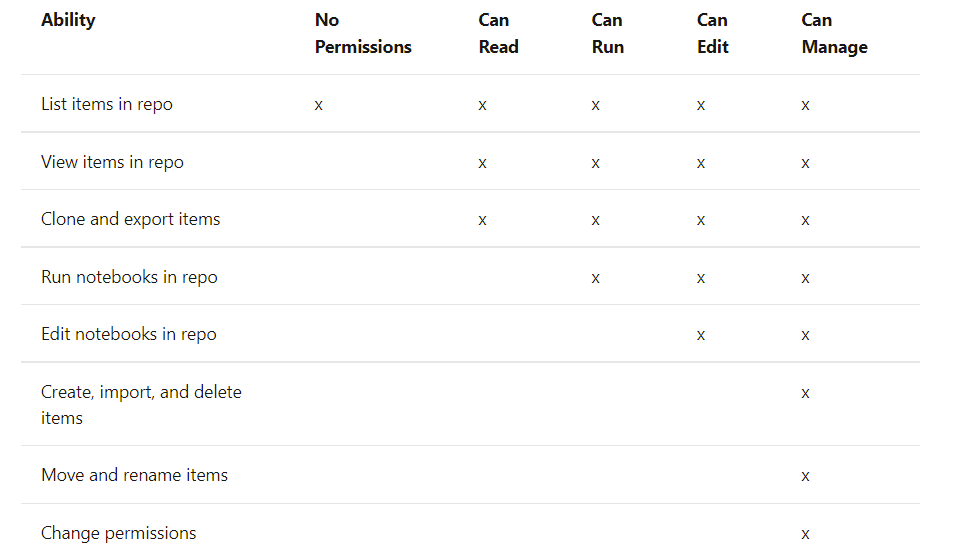
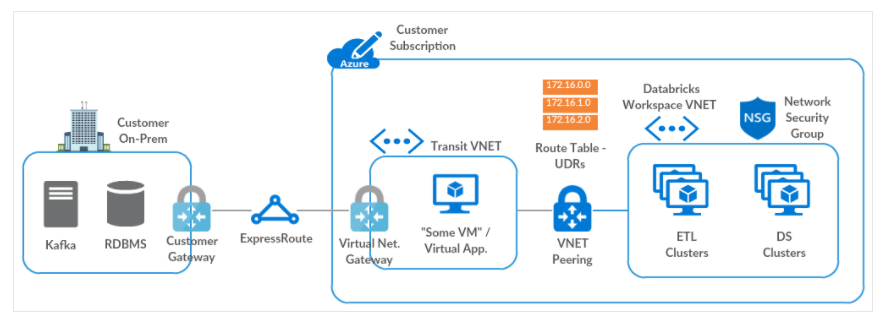
Un Gobierno del Dato consistente como base de una estrategia Data Driven global

Nuestro cliente es una marca mexicana líder mundial en el sector de la alimentación, con presencia en 33 países, más de 100 marcas, 3.000 puntos de venta y 200 centros de producción. Tiene como uno de sus pilares estratégicos la transformación digital que habilite el crecimiento y su evolución hacia una compañía ágil y centrada en el cliente, innovadora y con decisiones basadas en datos.
Un sector que está viviendo de pleno la transformación digital, desde los cambios en los modelos de fabricación con la Industria 4.0, la trazabilidad de los productos y su producción con el IoT, las nuevas estrategias en la Cadena de Suministro o el mismo e-Commerce y las redes sociales para la interacción con los nuevos clientes digitales.
Sus más de 10.000 productos, con heterogénea producción y distribución por sus geografías, la continua innovación y los cambios orgánicos, han supuesto un reto para la gestión eficiente de la información de las diferentes unidades. Y la necesidad de un marco de gobierno del dato como base de una gestión integrada de la tecnología, que asegure la implantación de modelos analíticos globales, son el punto de partida.
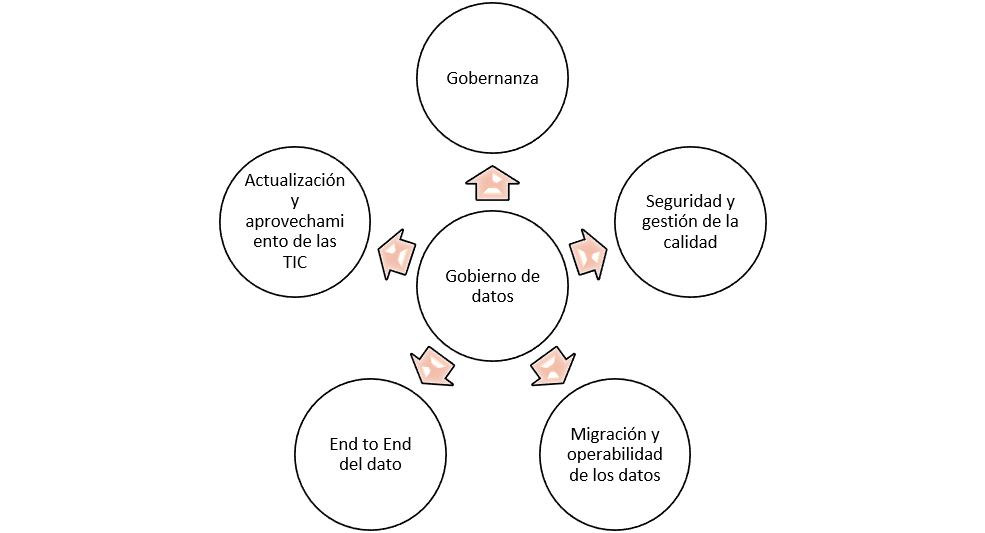
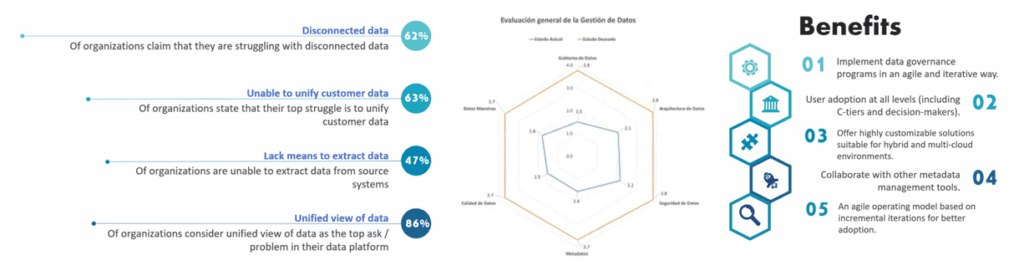
El equipo Bluetab ha realizado una detallada evaluación para las diferentes geografías del estado de madurez de los distintos ejes del gobierno y entre ellos la seguridad, la calidad, los datos maestros, los metadatos y la arquitectura. La armonización del estado de madurez es crítica para poder iniciar una estrategia de explotación global.
Una vez entendido ese mapa, la modelización del proyecto de México servirá como base para la el despliegue adaptado en cada entorno geográfico. Un proyecto que contempla procesos, políticas, dominios, roles, organización y estrategia, soportados por nuestro acelerador: Truedat
Con nuestra experiencia en este tipo de proyectos bajo arquitecturas cloud, además de asegurar esa armonización necesaria para dicha explotación global de la información, establecemos las bases para una evolución a modelos Data Mesh que aseguran a la vez, una gestión distribuida de los diferentes dominios de información.
CASOS DE ÉXITO