
Bluetab y la Universidad CEU San Pablo colaboran para formar líderes en analítica de datos
by Bluetab
Bluetab, compañía del grupo IBM especializada en soluciones de Data & AI, anuncia su colaboración con la Universidad CEU San Pablo en el Máster de Formación Permanente en Business Analytics for Strategic Management, un programa diseñado para formar a los futuros líderes en la toma de decisiones estratégicas basadas en datos.
Como parte de esta colaboración, profesionales de Bluetab participan activamente en la docencia del máster, aportando su experiencia práctica y visión de negocio en tres asignaturas clave: Data Analytics, Big Data y Machine Learning.
A través de esta iniciativa, Bluetab refuerza su compromiso con el desarrollo del talento en el ámbito del dato, acercando el conocimiento real del mercado y las tecnologías emergentes al entorno académico.
“En Bluetab creemos que compartir conocimiento es la mejor forma de impulsar la innovación. Colaborar con el CEU nos permite contribuir a la formación de los profesionales que liderarán la transformación data-driven de las organizaciones del futuro”
— Luis Malagón, CEO de Bluetab EMEA
El Máster en Business Analytics for Strategic Management de la CEU USP ofrece una visión integral del uso estratégico de los datos en la toma de decisiones empresariales, combinando rigor académico y aplicación práctica.
“Para nosotros, colaborar con empresas como Bluetab, que trabajan día a día en proyectos reales con clientes, es fundamental. Su experiencia práctica y visión aplicada aportan un valor incalculable al aprendizaje de nuestros alumnos, ayudándoles a conectar la teoría con los retos del mercado actual”
— Roberto Atanes Torres, Director del Máster en Business Analytics for Strategic Management
Con esta colaboración, Bluetab consolida su papel como actor clave en el ecosistema educativo y tecnológico, impulsando el aprendizaje continuo y la conexión entre la empresa y la universidad.
Sobre Bluetab
Bluetab, una compañía del grupo IBM, es especialista en proyectos de transformación basados en datos. Con 20 años de trayectoria y más de 1500 profesionales en Europa y América Latina, ayuda a las organizaciones a aprovechar el valor del dato mediante soluciones de analítica avanzada, inteligencia artificial y plataformas en la nube.
Sobre la Universidad CEU San Pablo
La Universidad CEU San Pablo es una de las cuatro universidades de iniciativa social y gestión privada de la Fundación Universitaria San Pablo CEU. Con más de 90 años de experiencia, mantiene un proyecto docente sólido que aspira a la formación integral del alumno a través de un método de enseñanza riguroso y actualizado, tanto teórico como práctico. Entre sus principales señas de identidad, destaca su compromiso con la excelencia educativa, la investigación, la inserción laboral de sus estudiantes y la internacionalización. Imparte numerosas titulaciones de grado y grados simultáneos, muchas de ellas total o parcialmente en inglés, en colaboración con instituciones internacionales de reconocido prestigio, como las universidades americanas de Boston, Chicago, UCLA y Fordham.
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar






by Bluetab

Technical Specialist

En muchas ocasiones, los costos en la nube pueden dispararse debido a una configuración inadecuada o a la falta de conocimiento sobre cómo aprovechar al máximo los servicios disponibles. En el caso de Google Cloud Platform (GCP), los servicios más utilizados para almacenamiento son Google Cloud Storage (GCS) y BigQuery. Sin embargo, sin un enfoque adecuado en su configuración y administración, pueden generar gastos innecesarios.
El objetivo de este artículo es proporcionar un conjunto de recomendaciones para optimizar el uso de estos servicios, enfocándonos en cómo configurar correctamente los buckets de GCS y las tablas de BigQuery, asegurándonos de que cada servicio esté alineado con las necesidades específicas de nuestra implementación. A lo largo del artículo, exploraremos las mejores estrategias para gestionar el ciclo de vida de los datos, decidir cuándo activar el versionado, cómo organizar la estructura de almacenamiento en función del uso o tipología de los datos y qué aspectos técnicos deben considerarse para mantener un control eficiente de los costos.
Además, vamos a abordar un conjunto de preguntas clave que debemos plantearnos al configurar estos servicios. Responder estas preguntas nos ayudará a tomar decisiones más informadas y evitar sobrecostos innecesarios.
También veremos cómo, utilizando las APIs de Google, podremos revisar los metadatos actuales de nuestros recursos, permitiéndonos auditar y mejorar la configuración de nuestros entornos de almacenamiento de forma sencilla y efectiva.
Utiliza clases de almacenamiento como Standard, Nearline, Coldline, y Archive según la frecuencia de acceso a los datos. Por ejemplo, si los datos no serán accedidos en los próximos 30 días, podrías moverlos a Nearline o Coldline para optimizar los costos.
Configura políticas de ciclo de vida para mover, eliminar o archivar objetos automáticamente basándote en la antiguedad de los mismos. Esto ayuda a reducir el costo de almacenamiento sin intervención manual.
Habilita el versionado solo cuando sea necesario. Si los datos cambian frecuentemente o si necesitas poder recuperar versiones anteriores de un archivo, el versionado es útil. Sin embargo, asegúrate de gestionar las versiones antiguas para no generar costos innecesarios por almacenamiento duplicado.
El particionamiento es una técnica que divide las tablas en segmentos más pequeños y manejables según una columna específica, como la fecha. En BigQuery, el particionamiento por fecha es común, ya que permite reducir la cantidad de datos escaneados durante las consultas. Al particionar las tablas, se optimizan las consultas al enfocarse solo en los segmentos de datos relevantes, lo que mejora el rendimiento y reduce los costos asociados con el procesamiento de grandes volúmenes de datos.
El clustering organiza los datos dentro de una tabla según una o más columnas de forma que los registros con valores similares se almacenan cerca unos de otros. Esta técnica es útil para mejorar la eficiencia de las consultas que filtran o agrupan por las columnas seleccionadas para el clustering. Al usar clustering junto con particionamiento, se puede mejorar aún más el rendimiento y reducir los costos de las consultas, ya que BigQuery puede leer menos datos y realizar búsquedas más rápidas sobre grandes conjuntos de datos.
Aunque el particionamiento y el clustering son poderosas herramientas para optimizar el rendimiento y reducir costos, también existen varios antipatrones que debes evitar en BigQuery. Un antipatrón común es no diseñar el esquema de particionamiento y clustering en función de cómo se realizan las consultas. Por ejemplo, particionar por una columna que no se usa frecuentemente en los filtros de las consultas puede resultar en un uso ineficiente del espacio y aumentar los costos de procesamiento. Otro antipatrón es tener un número excesivo de columnas con clustering, lo que puede llevar a una sobrecarga de administración y a tiempos de consulta más lentos.
Además, un error frecuente es realizar consultas sin un uso adecuado de las funciones de agregación o sin aplicar filtros eficientes, lo que puede provocar que se escaneen grandes volúmenes de datos innecesarios, aumentando los costos. Un antipatrón muy importante es el uso de SELECT *, que es común en algunas consultas pero puede ser extremadamente costoso en BigQuery. Esto se debe a que BigQuery es un sistema de bases de datos columnar, lo que significa que almacena los datos por columnas, no por filas. Al usar SELECT *, estás solicitando todos los datos de todas las columnas, lo que puede resultar en una gran cantidad de datos escaneados innecesariamente, aumentando los costos de la consulta y afectando el rendimiento. En su lugar, se recomienda seleccionar solo las columnas necesarias para la consulta, optimizando tanto el rendimiento como los costos.
Otro antipatrón es la sobrecarga de las consultas con un número elevado de uniones o subconsultas complejas, lo que puede impactar negativamente el rendimiento.
Google Cloud Storage (GCS) y BigQuery ofrecen configuraciones multirregión que permiten distribuir datos y consultas a través de múltiples ubicaciones geográficas, lo que puede proporcionar ventajas significativas en términos de disponibilidad y desempeño. Sin embargo, es fundamental comprender las ventajas y desventajas que tienen estas configuraciones para tomar decisiones informadas al diseñar arquitecturas.
Ventajas:
Desventajas:
Utiliza ubicaciones multirregión cuando la alta disponibilidad y la resiliencia sean esenciales para tu aplicación. Por ejemplo, aplicaciones críticas que deben estar siempre disponibles, incluso durante desastres regionales.
Si los costos son una preocupación, evalúa si realmente necesitas una configuración multirregión o si una ubicación única o una configuración regional puede ser suficiente para tus necesidades.
BigQuery
Ventajas:
Desventajas:
Si tu aplicación requiere análisis en tiempo real o consultas que involucren grandes volúmenes de datos distribuidos globalmente, usar una configuración multirregión en BigQuery puede mejorar significativamente el rendimiento.
Considera el costo de las transferencias interregionales si tu flujo de trabajo involucra consultas entre datos almacenados en diferentes regiones. Para evitar costos innecesarios, puede ser útil limitar las consultas a una región específica o consolidar los datos en una región centralizada.
Ten en cuenta la ubicación de tus usuarios y servicios, ya que elegir la región correcta puede impactar tanto el costo como el desempeño de las consultas.
En el entorno de la nube, controlar los costos y mantener el rendimiento óptimo de los servicios es esencial para una gestión eficiente de los recursos. Google Cloud ofrece varias herramientas que facilitan el monitoreo, la optimización de costos y el análisis del rendimiento de servicios como Google Cloud Storage (GCS) y BigQuery. A continuación, revisamos algunas de las herramientas más útiles disponibles en Google Cloud para gestionar ambos servicios.
Es una de las herramientas principales para gestionar y monitorear los costos asociados con todos los servicios de Google Cloud, incluyendo GCS y BigQuery. Proporciona visibilidad detallada sobre el uso de los servicios y las tarifas que se están generando.
Funcionalidades clave:
Usa Google Cloud Billing para establecer un control regular de los costos de GCS y BigQuery, y configura alertas para mantenerte dentro de los límites presupuestarios. Además, puedes crear informes personalizados para realizar un seguimiento más efectivo.
Utiliza las recomendaciones de optimización de Google Cloud Cost Management para ajustar la infraestructura de GCS y BigQuery a tus necesidades reales, asegurando una gestión de costos más eficaz.
Para gestionar el rendimiento de GCS y BigQuery, Google Cloud Monitoring es la herramienta recomendada. Esta herramienta permite visualizar el estado de los recursos de Google Cloud, incluidas las métricas de rendimiento de almacenamiento y consultas.
Funcionalidades clave:
Usa Google Cloud Monitoring para realizar un seguimiento constante de las métricas clave relacionadas con GCS y BigQuery, asegurando que ambas plataformas funcionen de manera eficiente y sin cuellos de botella que puedan afectar la experiencia del usuario o generar costos innecesarios.
Una de las principales preocupaciones en BigQuery es el rendimiento de las consultas. BigQuery Query Plan Explanation es una herramienta avanzada que permite examinar los planes de ejecución de las consultas y entender cómo BigQuery procesa los datos.
Funcionalidades clave:
Utiliza BigQuery Query Plan Explanation para revisar y optimizar las consultas que realizan un uso intensivo de recursos, asegurando que el procesamiento de datos se haga de la manera más eficiente posible.
Para poder tomar la mejor decisión te puedes basar en la siguiente serie de preguntas y escenarios planteados:
Para que puedas optimizar los costos aplicando las recomendaciones que se vieron anteriormente, es necesario que conozcas cómo están configurados los servicios, para esto puedes revisar varios ejemplos de código para obtener los metadatos de tus recursos en Google Cloud Storage (GCS) y BigQuery, utilizando las APIs de Google Cloud (en Python). Esto te permitirá obtener información sobre la configuración actual y ayudarte a identificar posibles mejoras o cambios.
pip install google-cloud-storage
Código para obtener metadatos del bucket:
import csv
import concurrent.futures
from google.cloud import storage
#cambiar nombre del project-id
client = storage.Client(project="project-id")
def obtener_metadatos_bucket(bucket):
metadatos = {
"nombre_bucket": bucket.name,
"ubicacion_bucket": bucket.location,
"clase_almacenamiento": bucket.storage_class,
"versionamiento_habilitado": bucket.versioning_enabled,
"reglas_ciclo_vida": str(bucket.lifecycle_rules) if bucket.lifecycle_rules else "No hay reglas",
}
objetos = []
blobs = client.list_blobs(bucket.name)
for blob in blobs:
objetos.append({
"nombre_objeto": blob.name,
"tamano_objeto": f"{blob.size} bytes"
})
return metadatos, objetos
def guardar_metadatos_csv(nombre_archivo, metadatos_buckets):
with open(nombre_archivo, mode='w', newline='') as file:
writer = csv.writer(file)
# Encabezados
writer.writerow(["Nombre del Bucket", "Ubicación", "Clase de Almacenamiento", "Versionamiento", "Reglas Ciclo de Vida", "Nombre del Objeto", "Tamaño del Objeto"])
# Escribir los metadatos de cada bucket
for metadatos, objetos in metadatos_buckets:
for objeto in objetos:
writer.writerow([
metadatos["nombre_bucket"],
metadatos["ubicacion_bucket"],
metadatos["clase_almacenamiento"],
metadatos["versionamiento_habilitado"],
metadatos["reglas_ciclo_vida"],
objeto["nombre_objeto"],
objeto["tamano_objeto"]
])
def procesar_bucket(bucket):
try:
metadatos, objetos = obtener_metadatos_bucket(bucket)
return metadatos, objetos
except Exception as e:
print(f"Error al procesar el bucket {bucket.name}: {e}")
return None
def obtener_y_guardar_metadatos():
metadatos_buckets = []
buckets = client.list_buckets()
# Usar ThreadPoolExecutor para paralelizar la carga de metadatos
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
futures = {executor.submit(procesar_bucket, bucket): bucket for bucket in buckets}
for future in concurrent.futures.as_completed(futures):
resultado = future.result()
if resultado:
metadatos_buckets.append(resultado)
guardar_metadatos_csv('metadatos_buckets.csv', metadatos_buckets)
print("Metadatos guardados en el archivo 'metadatos_buckets.csv'")
if __name__ == "__main__":
obtener_y_guardar_metadatos()
Este script te permitirá ver información sobre:
Este código obtiene metadatos sobre una tabla de BigQuery, como su esquema, particiones, y detalles de almacenamiento.
Instalar dependencias: Si aún no lo has hecho, instala el SDK de Google Cloud para BigQuery:
pip install google-cloud-bigquery Código para obtener metadatos de una tabla en BigQuery:
import csv
import concurrent.futures
from google.cloud import bigquery
from google.api_core.exceptions import NotFound
#cambiar nombre del project-id
client = bigquery.Client(project="project-id")
def obtener_metadatos_tabla(dataset_id, table_id):
try:
table_ref = client.dataset(dataset_id).table(table_id)
table = client.get_table(table_ref)
partition_field = "N/A"
if table.time_partitioning and table.time_partitioning.field:
partition_field = table.time_partitioning.field
metadatos = {
"dataset_id": dataset_id,
"table_id": table.table_id,
"descripcion": table.description,
"esquema": ', '.join([f"{field.name} ({field.field_type})" for field in table.schema]),
"partitioning_type": table.partitioning_type if table.partitioning_type else "No particionada",
"partition_field": partition_field, # Usamos la variable con la partición
"clustering_fields": ', '.join(table.clustering_fields) if table.clustering_fields else "No clustering",
"tamaño_bytes": table.num_bytes,
"numero_filas": table.num_rows
}
return metadatos
except NotFound:
print(f"Tabla no encontrada: {dataset_id}.{table_id}")
return None
def obtener_tablas_datasets():
metadatos_tablas = []
datasets = client.list_datasets()
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
futures = []
for dataset in datasets:
tablas = client.list_tables(dataset.dataset_id)
for tabla in tablas:
futures.append(executor.submit(obtener_metadatos_tabla, dataset.dataset_id, tabla.table_id))
for future in concurrent.futures.as_completed(futures):
metadatos = future.result()
if metadatos:
metadatos_tablas.append(metadatos)
return metadatos_tablas
def guardar_metadatos_csv(nombre_archivo, metadatos_tablas):
with open(nombre_archivo, mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=metadatos_tablas[0].keys())
writer.writeheader()
writer.writerows(metadatos_tablas)
def procesar_metadatos():
metadatos_tablas = obtener_tablas_datasets()
guardar_metadatos_csv('metadatos_tablas.csv', metadatos_tablas)
print("Metadatos guardados en el archivo 'metadatos_tablas.csv'")
if __name__ == "__main__":
procesar_metadatos()
Este script te permitirá obtener información clave sobre:
Para obtener más detalles acerca del uso y las métricas de tus servicios de GCS y BigQuery, puedes utilizar el servicio de Cloud Monitoring o la API de Stackdriver para obtener métricas sobre almacenamiento y consultas, pero esto va más allá de revisar metadatos y entra en el análisis de rendimiento.
En resumen, la optimización de los costos en Google Cloud Platform, especialmente en servicios clave como GCS y BigQuery, es fundamental para mantener un control eficiente sobre el gasto y maximizar el rendimiento de tus recursos. Siguiendo las recomendaciones sobre almacenamiento, ciclo de vida de los datos, versionado y seguridad, podrás tomar decisiones más informadas y alineadas con las necesidades específicas de tu proyecto. Además, con las herramientas y APIs disponibles, puedes auditar y ajustar continuamente tu infraestructura para asegurar que siempre estés aprovechando al máximo cada recurso. Con una gestión adecuada, los costos no tienen por qué ser un obstáculo, sino una oportunidad para mejorar la eficiencia y la escalabilidad de tu plataforma en la nube.
Technical Specialist
Te puede interesar






by Bluetab

Data Governance Specialist | Project Manager
En el gran universo de los proyectos, ya sea en el ámbito del gobierno del dato o en cualquier otra disciplina, hay una constante que a menudo se subestima: la gestión del cambio.
Puedes tener el proyecto más revolucionario, con un diseño impecable y tecnología de vanguardia, pero si no consigues que las personas lo adopten y lo integren en su día a día, el proyecto corre un alto riesgo de fracasar.

Un estudio de McKinsey señala que solo el 30% de las transformaciones empresariales logran cumplir con sus objetivos completos. (McKinsey & Company, 2021). Esta cifra pone de manifiesto una realidad alarmante: el éxito técnico y estratégico no garantiza el éxito organizacional.
La gestión del cambio actúa como un puente entre la solución y su implementación efectiva. Sin este puente, las iniciativas quedan en ideas que no logran materializarse en resultados tangibles.
En el contexto de proyectos de gobierno del dato, la gestión del cambio cobra una importancia aún mayor. Estas iniciativas no solo implican la implementación de nuevas herramientas o la definición de procesos, sino que también exigen una transformación cultural dentro de la organización.
Crear una cultura de datos, donde cada miembro de la empresa valore y utilice los datos como un activo estratégico, requiere tiempo, esfuerzo y, sobre todo, una estrategia sólida de cambio organizacional.
Muchos líderes se centran exclusivamente en los aspectos técnicos del proyecto, olvidando que el verdadero reto radica en cambiar comportamientos, hábitos y formas de trabajo consolidadas.
El éxito de un proyecto no radica solo en la calidad de su planificación o en el presupuesto invertido, sino en su capacidad para transformar a las personas y las organizaciones.
La gestión del cambio no es un complemento, es el núcleo que conecta la innovación con el impacto real.
Por ello, debemos abordarla con la misma rigurosidad y atención que cualquier otra fase del proyecto.
Como profesionales, tenemos la responsabilidad de no solo diseñar grandes soluciones, sino también de asegurarnos de que estas soluciones encuentren un lugar en las dinámicas diarias de las personas.
Solo así lograremos que nuestras ideas no se queden en el papel, sino que se conviertan en auténticos motores de cambio.
El éxito de un proyecto no radica solo en la calidad de su planificación o en el presupuesto invertido, sino en su capacidad para transformar a las personas y las organizaciones.
La gestión del cambio no es un complemento, es el núcleo que conecta la innovación con el impacto real.
Por ello, debemos abordarla con la misma rigurosidad y atención que cualquier otra fase del proyecto.
Como profesionales, tenemos la responsabilidad de no solo diseñar grandes soluciones, sino también de asegurarnos de que estas soluciones encuentren un lugar en las dinámicas diarias de las personas.
Solo así lograremos que nuestras ideas no se queden en el papel, sino que se conviertan en auténticos motores de cambio.
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar





by Bluetab

Data Architect | Data Tech Lead | Data Management | IA Engineer

Actualmente para las empresas impulsadas por los datos, la gestión efectiva e inteligencia artificial se han vuelto primordiales; cada clic, compra, contenido en redes sociales, telemetría de autos, maquinas e interacción genera información que, cuando se aprovecha correctamente, puede desbloquear nuevas ideas que aportan valor impulsando el crecimiento y la innovación, permitiendo diferenciarlas de otras empresas del mismo sector convirtiendo a la información generada en su ADN, pero ¿Cómo pueden las empresas asegurarse de que sus datos estén bien estructurados, sean escalables y estén disponibles cuando se necesiten? La respuesta radica en una sólida Arquitectura de Datos.
La Arquitectura de Datos es el plano que guía el diseño, la organización y la integración de los sistemas dentro y fuera de una organización, es el fundamento principal sobre el cual se construyen los productos de datos que permiten diferenciar a las empresas. A continuación, exploraremos los pilares clave una Arquitectura de Datos, tomando inspiración del libro «Diseñando Aplicaciones Intensivas en Datos» de Martin Kleppmann.
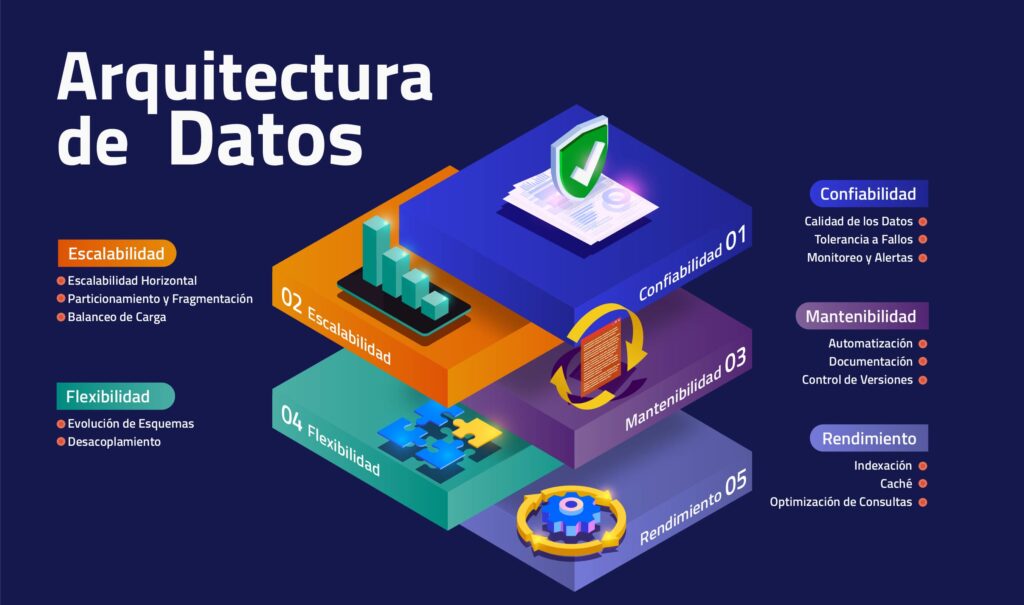
La confiabilidad es la base de cualquier arquitectura de datos, esto lo hace el pilar más importante entre todos. Hoy más que nunca, las empresas confían en sus datos para tomar decisiones críticas, y datos poco confiables pueden llevar a costosos errores, por ejemplo, en las industrias reguladas como lo es la Banca, los reportes generados para las entidades reguladoras deben ser confiables, de lo contrario podrían ser multados, impactando fuertemente al negocio, no solo en lo económico, en ocasiones también en su reputación, lograr la confiabilidad de los datos implica varias consideraciones:
A medida que las empresas crecen, también lo hace el volumen de información que manejan, la escalabilidad garantiza que los sistemas de datos puedan manejar cargas crecientes sin degradación del rendimiento. Las consideraciones clave para la escalabilidad incluyen:
La mantenibilidad se trata de garantizar que su arquitectura de datos siga siendo eficiente y manejable a medida que evoluciona, para esto, algunas estrategias son:
En el entorno empresarial actual, la adaptabilidad es crucial. Su arquitectura de datos debe ser lo suficientemente flexible como para adaptarse a los requisitos cambiantes.
El rendimiento es un aspecto crítico de la arquitectura de datos, especialmente para aplicaciones en tiempo real y de alto rendimiento, este pilar se debe definir junto con los usuarios de la plataforma ya que ellos debran definir los SLAs que debe cumplir la misma. Enfoque en:
En conclusión, una Arquitectura de Datos bien diseñada constituye la base de los productos de datos. Al priorizar la confiabilidad, la escalabilidad, la mantenibilidad, la flexibilidad y el rendimiento, las empresas pueden aprovechar todo el potencial de sus activos de datos. En una era en la que los datos son un activo estratégico, una sólida Arquitectura de Datos no es solo una opción; es una necesidad para un crecimiento y competitividad sostenibles.
Data Architect | Data Tech Lead | Data Management | IA Engineer
Te puede interesar



by Bluetab
Business Development Director

El reto de ser los mejores, no conformarnos y sobreexceder las expectativas de nuestros clientes, en verdad nos quita el sueño en /bluetab. Esto solo es posible si nos cuestionamos y reevaluamos de manera continua nuestras capacidades técnicas y habilidades para dirigir equipos de alto de desempeño, en cada cliente y en cada proyecto.
Existe la idea generalizada de que no es posible sentir bienestar y placer cumpliendo con nuestras obligaciones en el ámbito de nuestro trabajo o profesión. Al menos en la gran mayoría de los casos. Aun cuando haya cierta afinidad con las funciones asignadas, las obligaciones laborales se constituyen como un estricto intercambio de esfuerzo con un fin netamente económico y material, que coloca a nuestro trabajo en un concepto transaccional y frío
¿Ustedes que piensan?
Antes de explorar cualquier modelo de gestión de la felicidad en las organizaciones (desarrollados desde hace ya algunos años como parte de diversas corrientes de psicología positiva), debemos partir de un concepto aterrizado de “felicidad” para luego evaluar su impacto potencial en los resultados empresariales y el bienestar de sus trabajadores:
Aristóteles, por ejemplo, considera “la felicidad como el supremo bien y el fin último del hombre. Es la máxima aspiración humana y resulta del todo posible lograrla conjugando los bienes externos, los del cuerpo y los del alma. Es una actividad de acuerdo con la razón y, mejor aún, es la autorrealización misma del sujeto, que actuando bien se hace a sí mismo excelente y, con ello, feliz”.
Por otra parte, para Sócrates “la felicidad es el último bien del hombre y se logra con la práctica de la virtud. No se trata de la felicidad lograda de los placeres sensibles y fugaces, sino aquella serena y estable que proviene de la contemplación de la verdad y que se logra con la práctica de la virtud”.

En esta línea de pensamiento, existe una definición de felicidad que apunta más a la realización del ser humano y las emociones derivadas de ello, y no tanto a lo material, tangible o de alegría pasajera, al menos lo primero es esencial para poder disfrutar de todo el resto.
¿Qué pasaría si aplicamos esto en nuestra vida y nuestro entorno? ¿Creen que conseguiríamos más y mejores objetivos en cualquiera de los ámbitos en los que vivimos?
Se ha aprendido de generación en generación que alcanzar ciertos “objetivos de la vida” es lo más importante para obtener felicidad, misma que vamos postergando hasta alcanzar cada uno de ellos: cuando tengas tu título profesional, cuando tengas tu carro, cuando hagas ese viaje anhelado, cuando tengas pareja, cuando tengas tu casa, cuando te cases, cuando tengas hijos, y así la lista es interminable ya que al lograr un objetivo nace uno nuevo y el sentimiento de felicidad parece durar muy poco. Esto se ve exacerbado en esta era digital, donde el consumo de bienes, tecnología y experiencias se viraliza llegando a todos los rincones del planeta creando nuevas necesidades que, incluso, ni conocíamos.

Si invertimos esta fórmula, entendemos que el éxito en estos objetivos no son los que nos darán la felicidad sino al revés, siendo “personas felices” podemos alcanzar los objetivos de éxito que nos propongamos. Es más, llegarán de forma natural. Sería ese entonces el bien mayor y último de una persona, su autorrealización en función de la virtud y la excelencia, como comentan los filósofos citados.
Existe mucha bibliografía al respecto con algunas similitudes y definiciones clave. De un análisis general de una de las corrientes, podemos destacar como elementos indispensables para alcanzar la FELICIDAD a los siguientes:
En que podemos perfeccionar nuestras competencias para ser mejores aún, compartirlo con los demás, estrechar vínculos, enseñar lo que nos apasiona, alcanzar metas en equipo y obtener ese reconocimiento que nos hace sentir motivados y satisfechos por el trabajo bien hecho y su misión social con nuestros clientes. Así lo vemos en bluetab al menos.

Lo simple parece convertirse en lo más esencial de la vida y de nuestro trabajo. Esto nos lleva a pensar en un liderazgo diferente, uno emocional, donde gerenciamos una “transformación empresarial de alto impacto” poniendo el foco en que cada miembro de nuestra familia laboral sea feliz y experimente un bienestar real y a largo plazo, ayudándolo a crecer profesionalmente, a perfeccionarse, a brindarse a los demás y generando para sus funciones nuevos desafíos.
Como lo formuló Frederick Herzberg en su “teoría de los dos factores de 1959”: “para proporcionar motivación en el trabajo, se debe lograr el “enriquecimiento de tareas”, también llamado “enriquecimiento del cargo”, el cual consiste en la sustitución de las tareas más simples y elementales del cargo por tareas más complejas, que ofrezcan condiciones de desafío y satisfacción personal, para que así el empleado continúe con su crecimiento personal”.
En conclusión, toda organización que aspire a un cambio radical en sus resultados de negocio, mejorar el rendimiento de sus empleados, elevar el compromiso colectivo y lograr un crecimiento sostenible en el tiempo, debe prestar atención a la felicidad de quienes hacen la empresa día a día, impulsando dentro de su agenda estratégica iniciativas que atiendan de manera integral los siguientes tres factores de transformación desde la gente:

Sin duda hablamos de una filosofía de gestión organizacional basada en personas y, como todo modelo, debemos vivir nuestra experiencia al ponerlo en práctica, medir sus resultados y mejorarlo de manera continua. Alentamos a nuestros clientes y colegas a echarlo a andar con su gente.
Business Development Director
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar






by Bluetab
Cloud | Data & Analytics

Al igual que los recursos naturales, los datos actúan como el combustible impulsor de la innovación, la toma de decisiones y la creación de valor en diversos sectores. Desde las grandes empresas tecnológicas hasta los pequeños startups, la transformación digital está empoderando a los datos para convertirse en la base que genera conocimiento, optimiza la eficiencia y ofrece experiencias personalizadas a los usuarios.
La Gestión de Datos Maestros (MDM – Master Data Management) juega un papel esencial en proporcionar una estructura sólida para asegurar la integridad, calidad y consistencia de los datos en toda la organización.
A pesar de existir esta disciplina desde mediados de los años 90, algunas organizaciones no han adoptado MDM plenamente, esto puede ser por diversos factores, como la falta de comprensión de los beneficios, el coste, la complejidad y/o mantenimiento.
“Según encuesta de Gartner, el mercado global de MDM se valoró en 14.600 millones de dólares en 2022 y se espera que alcance los 24.000 millones de dólares en 2028, con una tasa de crecimiento anual compuesta (CAGR) del 8,2%”.

Antes de sumergirnos en el mundo de MDM, es importante comprender algunos conceptos relevantes del mismo.
Para gestionar los datos maestros, la primera pregunta que nos formulamos es ¿Qué son los datos maestros? Los datos maestros constituyen el conjunto de datos compartidos, esenciales y críticos para la ejecución de un negocio, que tienen vida útil (tiempo de vigencia) y contienen la información clave para el funcionamiento de la organización, como por ejemplo datos de clientes, productos, números de cuenta, entre otros.
Una vez definidos, es importante conocer sus características ya que los datos maestros son aquellos que se caracterizan por ser únicos, persistentes, íntegros, amplia cobertura, entre otros., esto es vital para garantizar la coherencia y calidad.
Por lo tanto, resulta fundamental contar con un enfoque que considere tanto los aspectos organizacionales (identificación de dueños del dato, usuarios impactados y matrices, entre otros) así como los procesos (relacionados a las políticas, flujos, procedimientos y mapeos), por lo tanto, nuestra propuesta como Bluetab sobre este enfoque se resume en cada una de estas dimensiones.

Otro aspecto que considerar desde nuestra experiencia en datos maestros, que resulta ser clave para iniciar con una implementación organizacional, es comprender su “ciclo de vida”, esto es que contenga:

La Gestión de los Datos Maestros o MDM es una “disciplina” y ¿por qué? Porque reúne un conjunto de conocimientos, políticas, prácticas, procesos y tecnologías (referido como herramienta tecnológica para recopilar, almacenar, gestionar y analizar los datos maestros). Esto perminte concluir es que es mucho más que una herramienta.
A continuación, proporcionamos algunos ejemplos que permitirán una mejor comprensión del aporrte de una adecuada gestión de datos maestros en diversos sectores:
En la Gestión de los Datos Maestros se realizan las siguientes operaciones fundamentales: la limpieza de datos, que elimina duplicados; el enriquecimiento de datos, que garantiza registros completos; y el establecimiento de una única fuente de verdad. El tiempo que pueda conllevar dependerá del estado de los registros que tenga la organización y sus objetivos de negocio. A continuación, podemos visualizar las tareas que se realizan:

Ahora que ya tenemos el concepto más claro, hay que tener en cuenta que la estrategia de la gestión de los datos maestros ponerlos en orden: actualizados, precisos, no redundancia, consistentes e íntegros.
¿Qué beneficios brinda la implementación de un MDM?
En bluetab hemos ayudado a clientes de diferentes industrias en su estrategia de datos maestros, tanto en la definición, análisis y diseño de la arquitectura como en la implementación de una solución integral. Derivado de ello, compartimos estos 05 pasos que te permitirán iniciar en la gestión de datos maestros:

A partir de nuestra experiencia, sugerimos considerar los siguientes aspectos a la hora de relevar / definir el proceso por cada dominio para la gestión de los datos maestros sujeto al alcance del proyecto:

En resumen, los datos maestros son los datos comunes más importantes para una organización y son la base de muchos procesos en el día a día a nivel empresarial. La gestión de datos maestros ayuda a garantizar que los mismos sean actualizados, precisos, no redundancia, consistentes, íntegros y compartidos adecuadamente, brindando beneficios tangibles en la calidad de los datos, eficiencia operativa, toma de decisiones informadas y experiencia del cliente. Esto es lo que contribuye al éxito y la competitividad de la organización en un entorno digital cada vez más impulsado por datos.
Si ha sido de interés este artículo, te agradecemos compartirlo y en bluetab estaremos deseosos de escuchar los desafíos y necesidades que tienes en tu organización en cuanto a datos maestros y de referencia.
Cloud | Data & Analytics
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar






