Basic AWS Glue concepts

Álvaro Santos
Senior Cloud Solution Architect

At Cloud Practice we aim to encourage adoption of the cloud as a way of working in the IT world. To help with this task, we are going to publish numerous good practice articles and use cases and others will talk about those key services within the cloud.
We present the basic concepts AWS Glue below.
What is AWS Glue?
AWS Glue is one of those AWS services that are relatively new but have enormous potential. In particular, this service could be very useful to all those companies that work with data and do not yet have powerful Big Data infrastructure.
Basically, Glue is a fully AWS-managed pay-as-you-go ETL service without the need for provisioning instances. To achieve this, it combines the speed and power of Apache Spark with the data organisation offered by Hive Metastore.
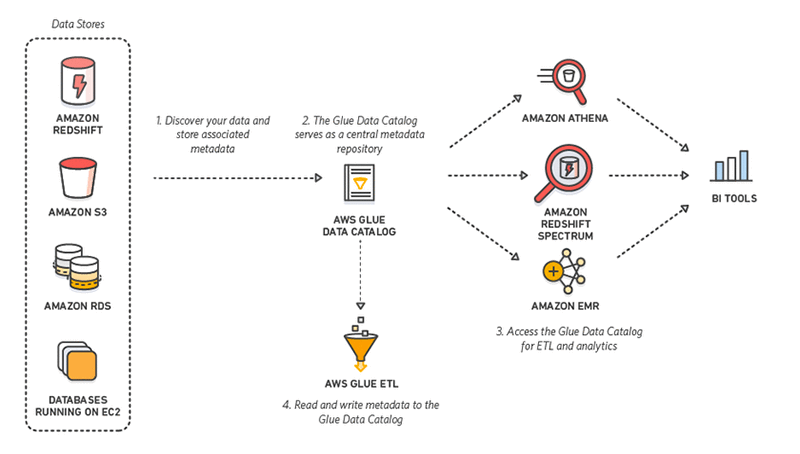
AWS Glue Data Catalogue
The Glue Data Catalogue is where all the data sources and destinations for Glue jobs are stored.
- Table is the definition of a metadata table on the data sources and not the data itself. AWS Glue tables can refer to data based on files stored in S3 (such as Parquet, CSV, etc.), RDBMS tables…
- Database refers to a grouping of data sources to which the tables belong.
- Connection is a link configured between AWS Glue and an RDS, Redshift or other JDBC-compliant database cluster. These allow Glue to access their data.
- Crawler is the service that connects to a data store, it progresses through a prioritised list of classifiers to determine the schema for the data and to generate the metadata tables. They support determining the schema of complex unstructured or semi-structured data. This is especially important when working with Parquet, AVRO, etc. data sources.
ETL
An ETL in AWS Glue consists primarily of scripts and other tools that use the data configured in the Data Catalogue to extract, transform and load the data into a defined site.
- Job is the main ETL engine. A job consists of a script that loads data from the sources defined in the catalogue and performs transformations on them. Glue can generate a script automatically or you can create a customised one using the Apache Spark API in Python (PySpark) or Scala. It also allows the use of external libraries which will be linked to the job by means of a zip file in S3.
- Triggers are responsible for running the Jobs. They can be run according to a timetable, a CloudWatch event or even a cron command.
- Workflows is a set of triggers, crawlers and jobs related to each other in AWS Glue. You can use them to create a workflow to perform a complex multi-step ETL, but that AWS Glue can run as a single entity.
- ML Transforms are specific jobs that use Machine Learning models to create custom transforms for data cleaning, such as identifying duplicate data, for example.
- Finally, you can also use Dev Endpoints and Notebooks, which make it faster and easier to develop and test scripts.
Examples
Sample ETL script in Python:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
## Read Data from a RDS DB using JDBC driver
connection_option = {
"url": "jdbc:mysql://mysql–instance1.123456789012.us-east-1.rds.amazonaws.com:3306/database",
"user": "test",
"password": "password",
"dbtable": "test_table",
"hashexpression": "column_name",
"hashpartitions": "10"
}
source_df = glueContext.create_dynamic_frame.from_options('mysql', connection_options = connection_option, transformation_ctx = "source_df")
job.init(args['JOB_NAME'], args)
## Convert DataFrames to *AWS Glue* 's DynamicFrames Object
dynamic_df = DynamicFrame.fromDF(source_df, glueContext, "dynamic_df")
## Write Dynamic Frame to S3 in CSV format
datasink = glueContext.write_dynamic_frame.from_options(frame = dynamic_df, connection_type = "s3", connection_options = {
"path": "s3://glueuserdata"
}, format = "csv", transformation_ctx = "datasink")
job.commit() Creating a Job using a command line:
aws glue create-job --name python-job-cli --role Glue_DefaultRole \
--command '{"Name" : "my_python_etl", "ScriptLocation" : "s3://SOME_BUCKET/etl/my_python_etl.py"}' Running a Job using a command line:
aws glue start-job-run --job-name my_python_etl AWS has also published a repository with numerous example ETLs for AWS Glue.
Security
Like all AWS services, it is designed and implemented to provide the greatest possible security. Here are some of the security features that AWS GLUE offers:
- Encryption at Rest: this service supports data encryption (SSE-S3 or SSE-KMS) at rest for all objects it works with (metadata catalogue, connection password, writing or reading of ETL data, etc.).
- Encryption in Transit: AWS offers Secure Sockets Layer (SSL) encryption for all data in motion, AWS Glue API calls and all AWS services, such as S3, RDS…
- Logging and monitoring: is tightly integrated with AWS CloudTrail and AWS CloudWatch.
- Network security: is capable of enabling connections within a private VPC and working with Security Groups.
Price
AWS bills for the execution time of the ETL crawlers / jobs and for the use of the Data Catalogue.
- Crawlers: only crawler run time is billed. The price is $0.44 (eu-west-1) per hour of DPU (4 vCPUs and 16 GB RAM), billed in hourly increments.
- Data Catalogue: you can store up to one million objects at no cost and at $1.00 (eu-west-1) per 100,000 objects thereafter. In addition, $1 (eu-west-1) is billed for every 1,000,000 requests to the Data Catalogue, of which first million is free.
- ETL Jobs: billed only for the time the ETL job takes to run. The price is $0.44 (eu-west-1) per hour of DPU (4 vCPUs and 16 GB RAM), billed by the second.
Benefits
Although it is a young service, it is quite mature and is being used a lot by clients all over the AWS world. The most important features it offers us are:
- It automatically manages resource escalation, task retries and error handling.
- It is a Serverless service, AWS manages the provisioning and scaling of resources to execute the commands or queries in the Apache Spark environment.
- The crawlers are able to track your data, suggest schemas and store them in a centralised catalogue. They also detect changes in them.
- The Glue ETL engine automatically generates Python / Scala code and has a programmer including dependencies. This facilitates development of the ETLs.
- You can directly query the S3 data using Athena and Redshift Spectrum using the Glue catalogue.
Conclusions
Like any database, tool, or service offered, AWS Glue has certain limitations that would need to be considered to adopt it as an ETL service. You therefore need to bear in mind that:
- It is highly focused on working with data sources in S3 (CSV, Parquet, etc.) and JDBC (MySQL, Oracle, etc.).
- The learning curve is steep. If your team comes from the traditional ETL world, you will need to wait for them to pick up understanding of Apache Spark.
- Unlike other ETL tools, it lacks default compatibility with many third-party services.
- It is not a 100% ETL tool in use and, as it uses Spark, code optimisations need to be performed manually.
- Until recently (April 2020), AWS Glue did not support streaming data. It is too early to use AWS Glue as an ETL tool for real-time data.
Do you want to know more about what we offer and to see other success stories?
My name is Álvaro Santos and I have been working as Solution Architect for over 5 years. I am certified in AWS, GCP, Apache Spark and a few others. I joined Bluetab in October 2018, and since then I have been involved in cloud Banking and Energy projects and I am also involved as a Cloud Master Partitioner. I am passionate about new distributed patterns, Big Data, open-source software and anything else cool in the IT world.
SOLUTIONS, WE ARE EXPERTS
You may be interested in




